
我们写一个.c文件,想要运行它,需要经过编译、汇编、链接等过程。在此过程中,文件从.c->.i->.s->-o->可执行文件

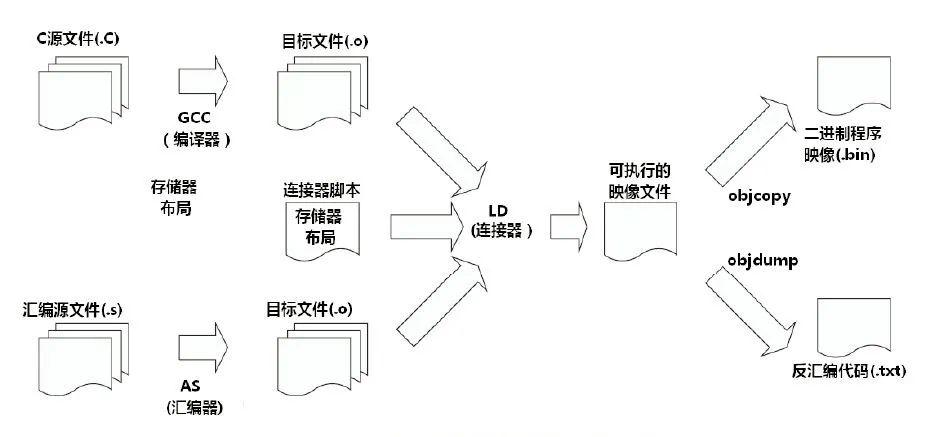
0.案例
下面以一个例子为例详细了解这个过程
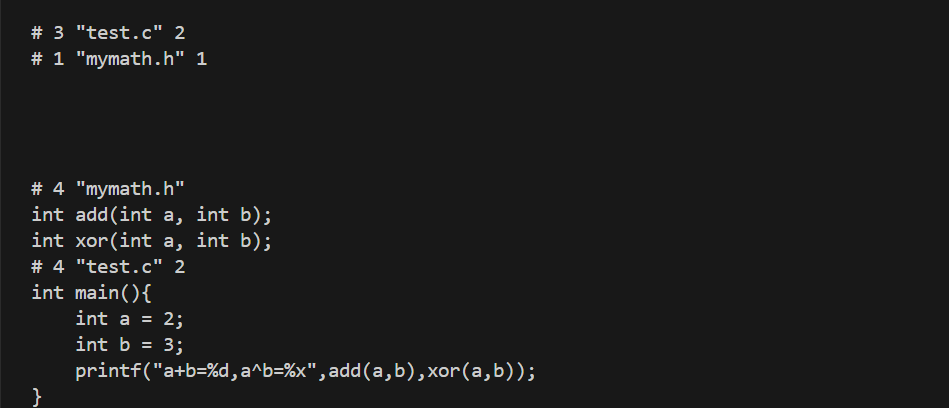
写一个简单的test.c,定义头文件mymath.h,具体逻辑写在mymath.c中
// test.c
#include <stdio.h>
#include "mymath.h"// 自定义头文件
int main(){
int a = 2;
int b = 3;
printf("a+b=%d,a^b=%x",add(a,b),xor(a,b));
}
// mymath.h
#ifndef MYMATH_H
#define MYMATH_H
int add(int a, int b);
int xor(int a, int b);
#endif
int add(int a, int b){
return a+b;
}
int xor(int a, int b){
return a^b;
}接下来以gcc编译器为例编译test.c文件
1.预处理
预编译把一些#define的宏定义完成文本替换,然后将#include的文件里的内容复制到.c文件里,如果.h文件里还有.h文件,就递归展开。
参数:-E(注意大写)
gcc -E test.c -o test.i
cat test.i会发现.i文件相对于.c文件多了#include里的内容,代码量相对之前增加了很多
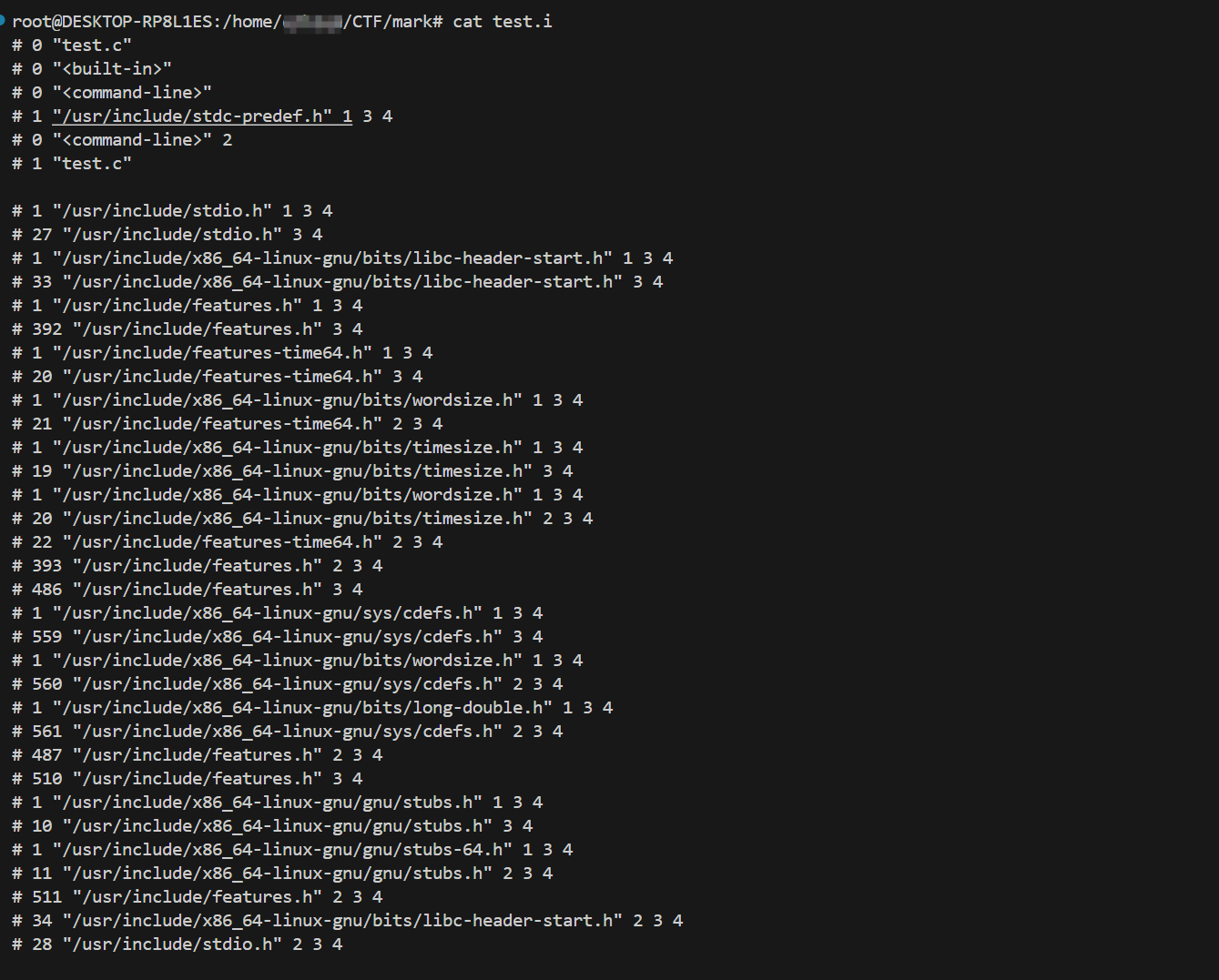
以及把mymath.h也整合进来
2.编译
将经过预处理之后的程序转换成特定汇编代码(assembly code),汇编代码就是二进制代码翻译来的给人看的代码,它和二进制代码一一对应
参数:-S(注意大写)
gcc -S test.i -o test.s
cat test.s .file "test.c"
.text
.section .rodata
.LC0:
.string "a+b=%d,a^b=%x"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
pushq %rbx
subq $24, %rsp
.cfi_offset 3, -24
movl $2, -24(%rbp)
movl $3, -20(%rbp)
movl -20(%rbp), %edx
movl -24(%rbp), %eax
movl %edx, %esi
movl %eax, %edi
call xor@PLT
movl %eax, %ebx
movl -20(%rbp), %edx
movl -24(%rbp), %eax
movl %edx, %esi
movl %eax, %edi
call add@PLT
movl %ebx, %edx
movl %eax, %esi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
movq -8(%rbp), %rbx
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:从以上代码中能看出程序的运行逻辑,以及一些调试信息
例如:
#文件名
.file "test.c"
#调试指令(.cfi_*):
.cfi_startproc
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
.cfi_def_cfa_register 6
.cfi_endproc
#链接信息
call xor@PLT
call add@PLT
call printf@PLT #PLT(Procedure Linkage Table) 是一个机制,用于在运行时动态链接和调用外部函数。
#版本信息
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
#栈保护和属性信息
.section .note.GNU-stack,"",@progbits #标记程序是否启用了栈保护(Stack Protection)通常,这意味着程序的栈不可以执行,防止某些类型的攻击(如栈溢出攻击)。
.section .note.gnu.property,"a"
#标记节
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
我们可以从汇编代码中获取程序的调试信息和编译器信息,这对于识别汇编代码的编译器和目标处理器架构非常重要。(后面将举例重点讨论)
3.汇编
将上一步的汇编代码转换成机器码(machine code),这一步产生的文件叫做目标文件,是二进制格式。
参数:-c
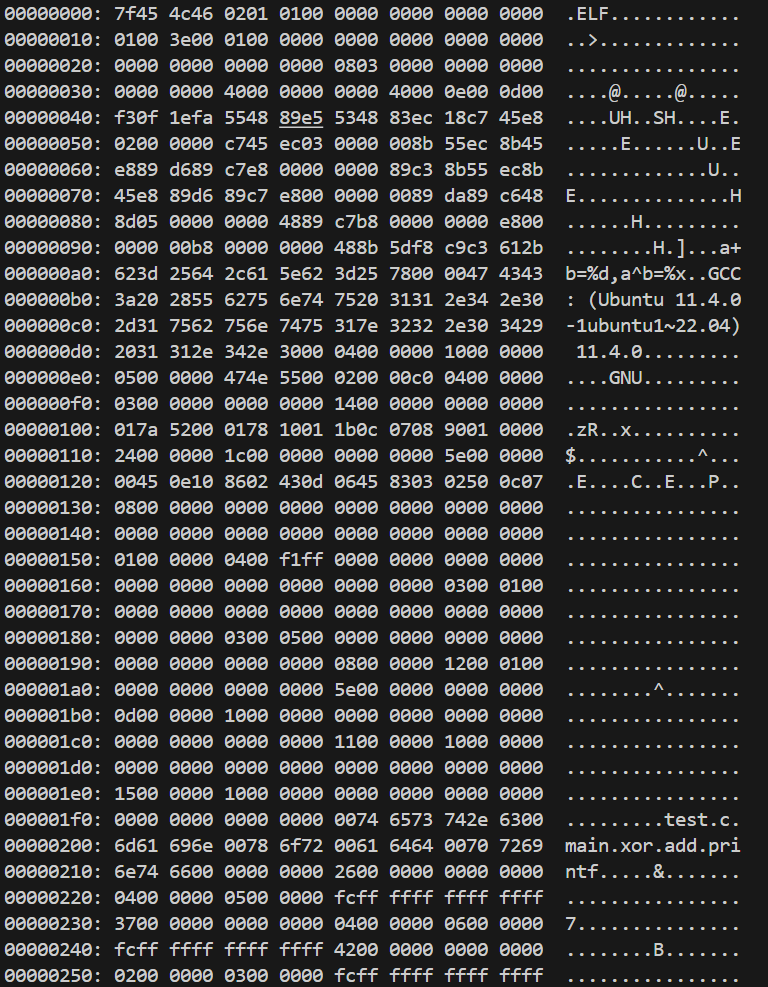
gcc -c test.s -o test.o
cat test.o
xxd test.o可以发现输出乱码,因为是二进制文件

xxd可以将二进制文件转为十六进制输出,以查看十六进制数据和对应的 ASCII 字符,实现类似010的功能。可以看见ELF文件头以及一些调试信息和文件信息
4.链接
链接过程将多个目标文以及所需的库文件(.so等)链接成最终的可执行文件(executable file)。
注意,在链接前需要将mymath.c也编译汇编成.o文件,过程同上,也可以一步到位
gcc -c mymath.c -o mymath.o参数:无
gcc test.o mymath.o -o test这就生成了可执行文件test
./test
#a+b=5,a^b=1下面具体介绍每一步所用到的工具
1.编译器
在本案例中,我们使用了gcc这一编译器
编译器(compiler)是一种计算机程序,它能将某种编程语言写成的源代码(C、C++、Java等)转换成目标语言(汇编语言或机器代码),它主要的目的是将便于人编写、阅读、维护的高级计算机语言所写作的源代码程序,翻译为计算机能解读、运行的低阶机器语言的程序,也就是可执行文件
一个现代编译器的主要工作流程即与案例中从.c到可执行文件的全过程类似。
1.1 按平台分类
Linux
- GCC(GNU Compiler Collection):这是GNU项目的主要编译器,它支持多种编程语言,包括C、C++、Objective-C、Fortran、Ada、Go等。支持多种平台和架构,包括 x86、x86_64、ARM、MIPS 等。
- Clang (LLVM):一个开源的 C、C++、Objective-C 编译器,基于 LLVM(Low-Level Virtual Machine)框架。它是 GCC 的替代品,具有更好的错误提示和诊断信息。
Windows
MSVC (Microsoft Visual C++,也称Visual C++、、VC++或VC):这是Microsoft公司的C、C++、C++/CLI编译器,是Visual Studio IDE的一部分。MSVC遵循Microsoft自己的C++标准,广泛用于 Windows 平台上的开发。它主要支持 Windows API 和 COM(Component Object Model)编程。(ps:就是许多学校机房里写c语言用的编译器,比较传统)
MinGW (Minimalist GNU for Windows):MinGW 是一个用于 Windows 的开源 GCC 变种,它提供了 GNU 工具链(包括 GCC、GDB 等)以支持 C、C++ 等语言的编译。它能够生成本地的 Windows 可执行文件(PE 文件)。(提供类似 Linux 下的开发环境)
Cygwin:一个提供类 Unix 环境的工具,允许用户在 Windows 上使用 Unix 风格的命令行工具和开发工具(如 GCC)。
Clang(LLVM)
macOS
- Xcode:这是Apple公司的开发工具集,它包含了Apple的Clang编译器,以及其他一些工具,比如Interface Builder、AppleScript Studio等。
- GCC
- LLVM Clang
1.2 结构
重申:编译器就是一个程序
编译器主要由两个部分组成:前端和后端
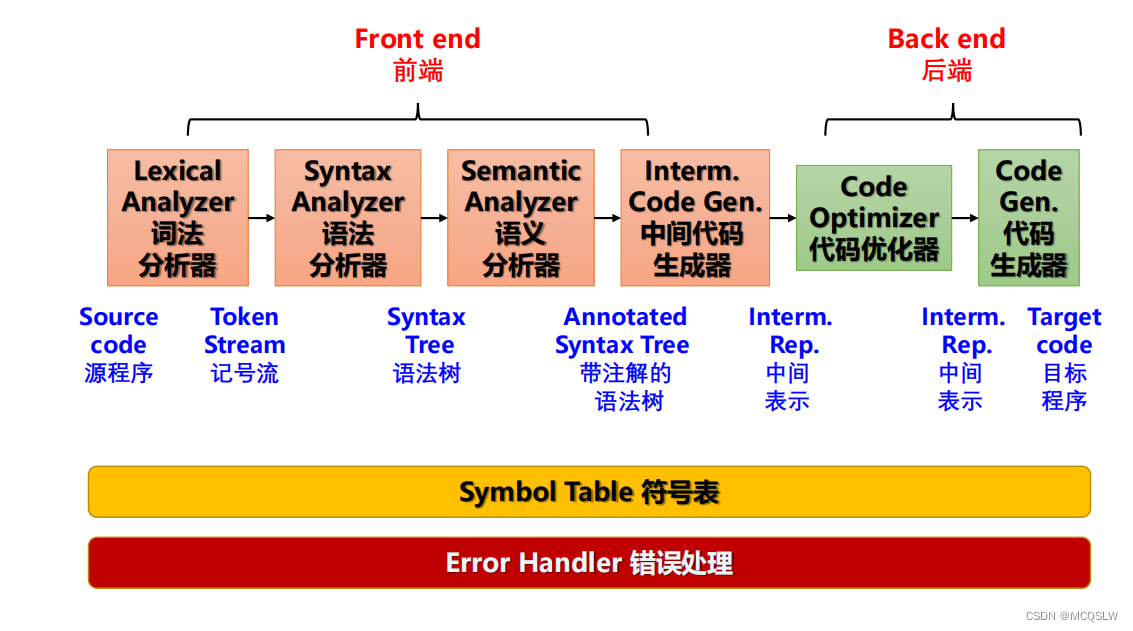
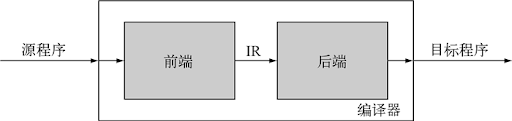
前端负责处理源代码的语法和语义分析,将源代码转换为一种抽象的中间表示(Intermediate Representation, IR),这种表示是平台无关的。
后端的任务是将优化后的中间代码转换为目标机器代码或汇编代码,生成可供执行的最终代码。
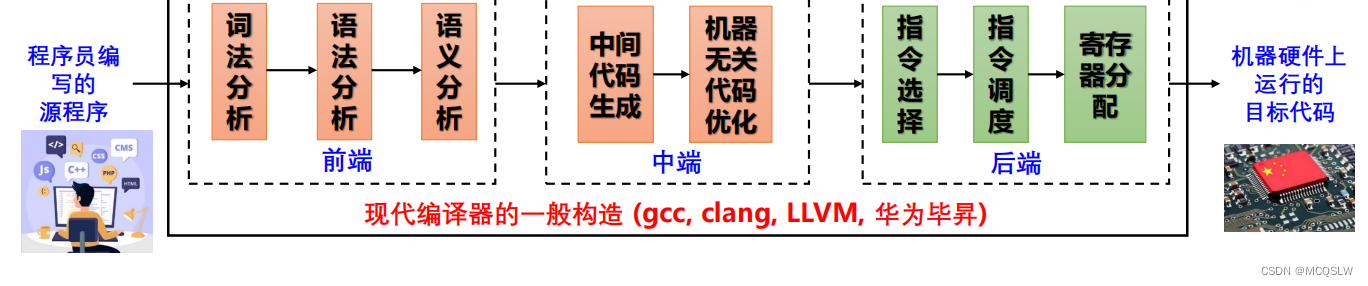
大多数现代编译器采用 模块化 设计,每个模块负责编译过程中的一个特定任务。下面详细说明每一个模块
1 词法分析器
词法分析器(lexical analysis或 Lexer):是编译器的第一阶段,负责将源代码文本转换为一系列的记号(tokens)。
输入:源代码
输出:一系列的记号,每个记号对应着语言中的一个基本元素。
组成:
- 字符分类
- 正则匹配
- 缓冲区:读取字符流并缓冲,处理字符时需要查看当前字符和接下来的字符
- 错误检测
基本流程:
- 扫描器:识别所能处理的标记中可能包含的所有字符序列
- 标记生成器:标记化(tokenization)即将输入字符串分割为标记、进而将标记进行分类的过程。生成的标记随后便被用来进行语法分析
eg:针对如下c语言表达式
sum=3+2;标记化后得到下表内容
| sum | 标识符 |
|---|---|
| = | 赋值操作符 |
| 3 | 数字 |
| + | 加法操作符 |
| 2 | 数字 |
| ; | 语句结束 |
示例代码如下:
import re
# 定义正则表达式模式
token_specification = [
('NUMBER', r'\d+(\.\d*)?'), # 数字
('IDENTIFIER', r'[A-Za-z_][A-Za-z0-9_]*'), # 标识符
('ASSIGN', r'='), # 赋值运算符
('PLUS', r'\+'), # 加法运算符
('MINUS', r'-'), # 减法运算符
('MULT', r'\*'), # 乘法运算符
('DIV', r'/'), # 除法运算符
('LPAREN', r'\('), # 左括号
('RPAREN', r'\)'), # 右括号
('LBRACE', r'\{'), # 左花括号
('RBRACE', r'\}'), # 右花括号
('IF', r'\bif\b'), # if 关键字
('RETURN', r'\breturn\b'), # return 关键字
('WHITESPACE', r'[ \t\n]+'), # 跳过空白字符
('MISMATCH', r'.'), # 匹配任何字符(错误处理)
]
# 合并所有的正则表达式
master_pattern = '|'.join('(?P<%s>%s)' % pair for pair in token_specification)
# 词法分析器
def lexer(code):
line_num = 1
line_start = 0
for mo in re.finditer(master_pattern, code):
kind = mo.lastgroup
value = mo.group()
if kind == 'WHITESPACE':
continue
elif kind == 'MISMATCH':
raise RuntimeError(f'Illegal character "{value}" at line {line_num}')
elif kind == 'NUMBER':
value = float(value) if '.' in value else int(value)
elif kind == 'IDENTIFIER' and value in {'if', 'return'}:
kind = value.upper()
yield kind, value
# 测试代码
code = '''
int main() {
int a = 5;
float b = 3.14;
if (a > b) {
return 0;
}
}
'''
# 执行词法分析
for token in lexer(code):
print(token)
'''
输出
('IDENTIFIER', 'int')
('IDENTIFIER', 'main')
('LPAREN', '(')
('RPAREN', ')')
('LBRACE', '{')
('IDENTIFIER', 'int')
('IDENTIFIER', 'a')
('ASSIGN', '=')
('NUMBER', 5)
('SEMICOLON', ';')
('IDENTIFIER', 'float')
('IDENTIFIER', 'b')
('ASSIGN', '=')
('NUMBER', 3.14)
('SEMICOLON', ';')
('IF', 'if')
('LPAREN', '(')
('IDENTIFIER', 'a')
('ASSIGN', '=')
('IDENTIFIER', 'b')
('RBRACE', '}')
'''2 语法分析器
语法分析器(Syntax Analyzer 或 Parser):根据编程语言的语法规则,检查输入的记号序列是否符合该语言的语法规范,并生成结构化的语法树供后续的编译阶段(如语义分析和代码生成)使用。
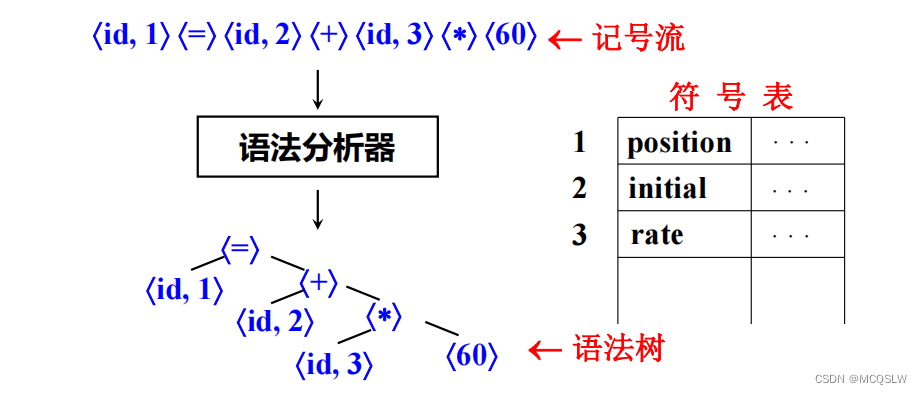
输入:记号流
输出:抽象语法树(Abstract Syntax Tree, AST)。AST是一种树状结构,每个节点表示程序中的一个构造单元(如语句、表达式、声明等),它的结构反映了源代码的语法结构。
就拿案例中的.c代码来生成AST,要用到clang编译器
Clang 提供了一个名为
-Xclang的选项,可以输出 AST。你可以使用以下命令生成 C 程序的 AST:clang -Xclang -ast-dump -fsyntax-only test.c
内容如下:
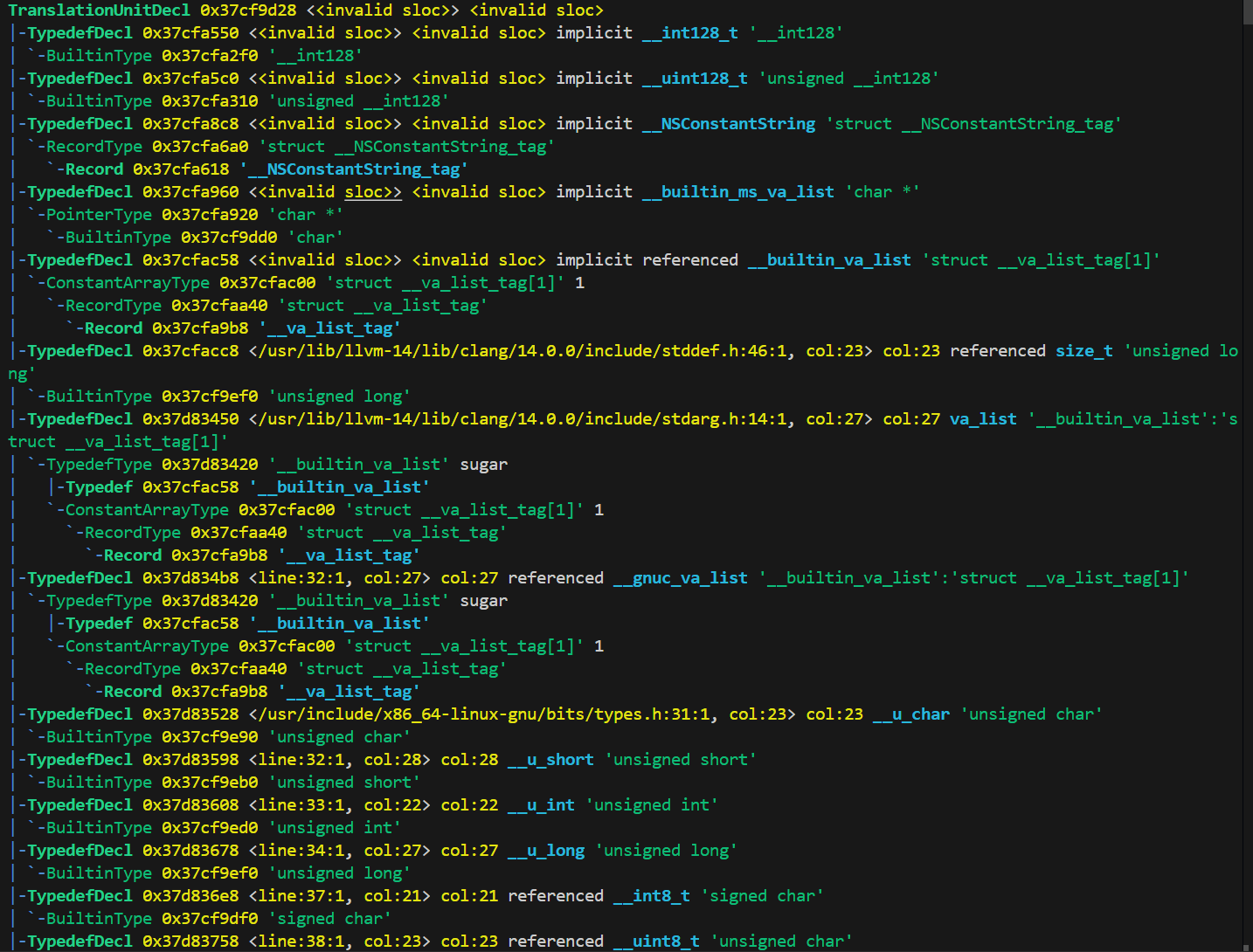
内容很多,这里只截了一小部分,不过很明显能看出这是程序中的typedef类型的定义,都是一些初始化内容,看最后面
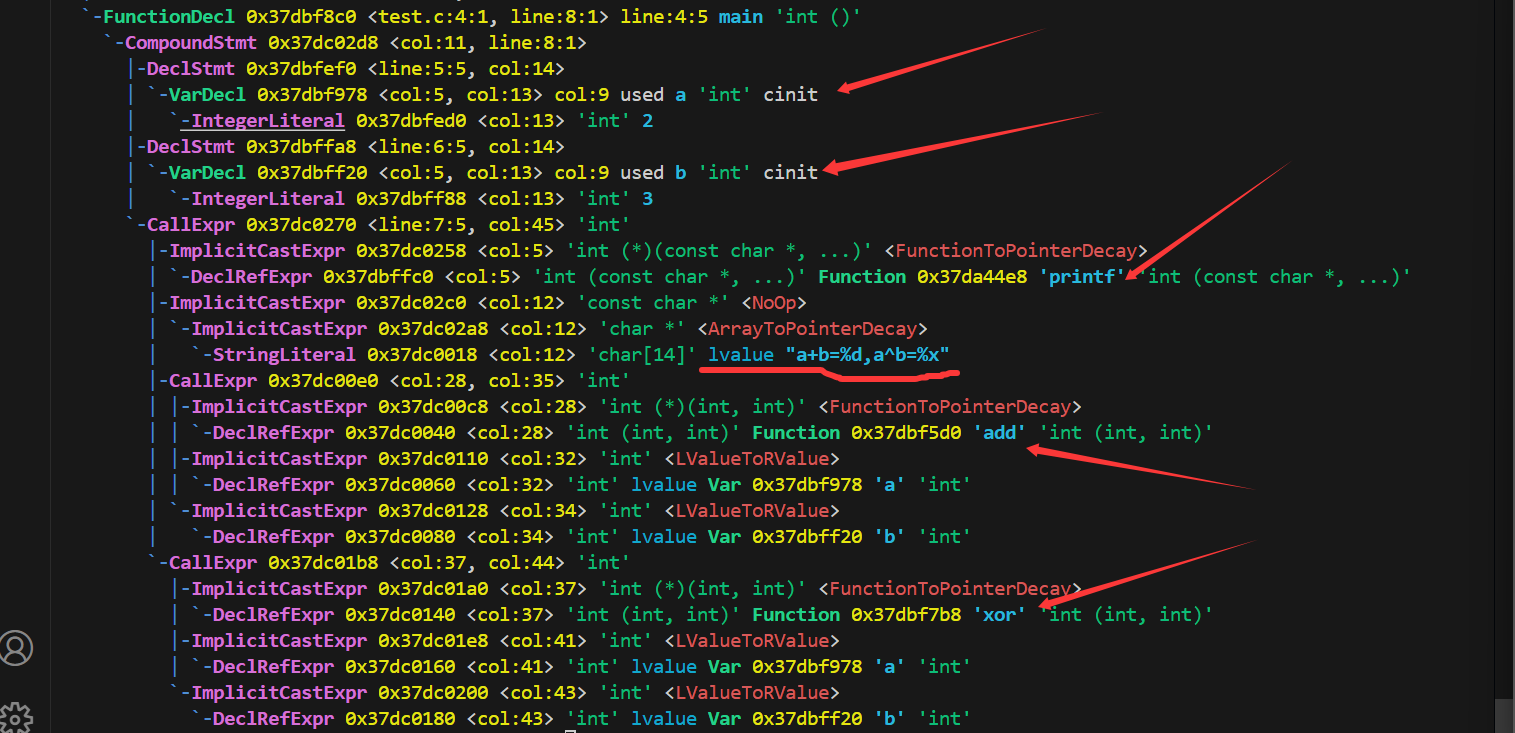
这里是对main的调用,也就是主要逻辑,其中
DeclStmt 变量声明:给int类型的a和b进行初始化,值分别为2和3
CallExpr调用表达式:调用printf来输出一条字符串,格式化输出结果是 a + b = %d, a ^ b = %x,另外还调用了add和xor
ImplicitCastExpr 隐式类型转换:FunctionToPointerDecay:将函数 printf、add 和 xor 转换为函数指针,ArrayToPointerDecay:将字符串文字("a+b=%d,a^b=%x")转换为指向字符的指针(char*)。
由此可见,通过抽象语法树(AST),我们能够还原程序的大部分逻辑结构。但是AST 主要关注的是语法和结构,它不直接包含程序的具体行为或运行时状态,因此它并不能完全还原程序的所有逻辑
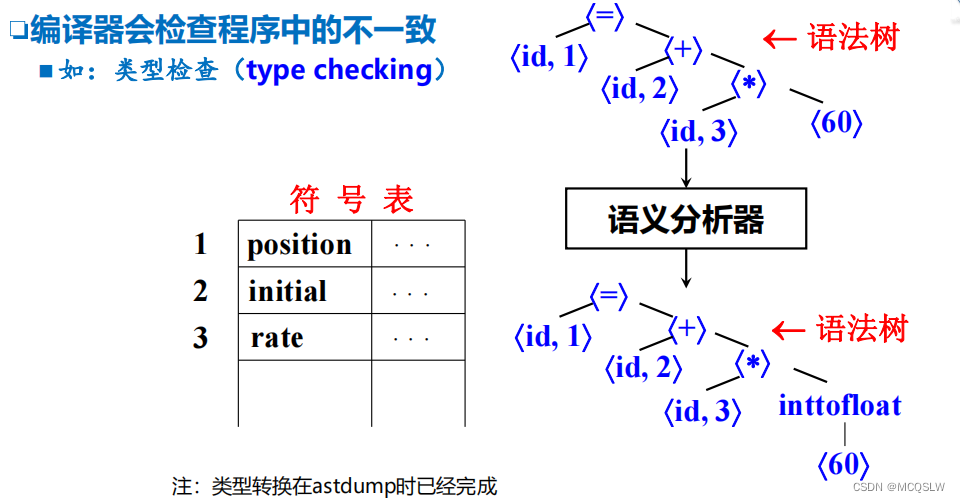
3 语义分析
做检查以修正错误或者收集信息
4 中间代码生成器**(Intermediate Code Generator)**
生成介于源程序和汇编之间的中间代码(IR)。
类型:三地址码,抽象语法树,汇编级中间代码
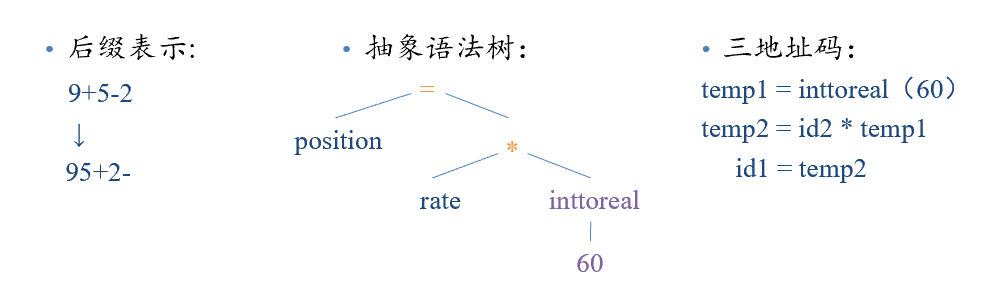
以案例的test.c为例
查看GIMPLE IR
gcc -fdump-tree-gimple -c test.c
cat test.c.006t.gimpleIR如下:
int main ()
{
int D.2355;
{
int a;
int b;
a = 2;
b = 3;
_1 = xor (a, b);
_2 = add (a, b);
printf ("a+b=%d,a^b=%x", _2, _1);
}
D.2355 = 0;
return D.2355;
}看起来很简单清晰,GIMPLE 是一种简化的三地址代码,所有复杂表达式都会被分解成简单的赋值和函数调用。
查看更低级的IR(经过优化的 GIMPLE IR)
gcc -fdump-tree-optimized -c test.c;; Function main (main, funcdef_no=0, decl_uid=2350, cgraph_uid=1, symbol_order=0)
int main ()
{
int b;
int a;
int D.2355;
int _1;
int _2;
int _9;
<bb 2> :
a_3 = 2;
b_4 = 3;
_1 = xor (a_3, b_4);
_2 = add (a_3, b_4);
printf ("a+b=%d,a^b=%x", _2, _1);
_9 = 0;
<bb 3> :
<L0>:
return _9;
}也挺清晰。
再低级的RTL IR:
gcc -fdump-rtl-expand -c test.c;; Function main (main, funcdef_no=0, decl_uid=2350, cgraph_uid=1, symbol_order=0)
Partition 1: size 4 align 4
b_4
Partition 0: size 4 align 4
a_3
;; Generating RTL for gimple basic block 2
;; Generating RTL for gimple basic block 3
try_optimize_cfg iteration 1
Merging block 3 into block 2...
Merged blocks 2 and 3.
Merged 2 and 3 without moving.
Merging block 4 into block 2...
Merged blocks 2 and 4.
Merged 2 and 4 without moving.
Removing jump 29.
Merging block 5 into block 2...
Merged blocks 2 and 5.
Merged 2 and 5 without moving.
try_optimize_cfg iteration 2
;;
;; Full RTL generated for this function:
;;
(note 1 0 3 NOTE_INSN_DELETED)
(note 3 1 2 2 [bb 2] NOTE_INSN_BASIC_BLOCK)
(note 2 3 5 2 NOTE_INSN_FUNCTION_BEG)
(insn 5 2 6 2 (set (mem/c:SI (plus:DI (reg/f:DI 77 virtual-stack-vars)
(const_int -8 [0xfffffffffffffff8])) [1 a+0 S4 A64])
(const_int 2 [0x2])) "test.c":5:9 -1
(nil))
(insn 6 5 7 2 (set (mem/c:SI (plus:DI (reg/f:DI 77 virtual-stack-vars)
(const_int -4 [0xfffffffffffffffc])) [1 b+0 S4 A32])
(const_int 3 [0x3])) "test.c":6:9 -1
(nil))
(insn 7 6 8 2 (set (reg:SI 86)
(mem/c:SI (plus:DI (reg/f:DI 77 virtual-stack-vars)
(const_int -4 [0xfffffffffffffffc])) [1 b+0 S4 A32])) "test.c":7:5 -1
(nil))
(insn 8 7 9 2 (set (reg:SI 87)
(mem/c:SI (plus:DI (reg/f:DI 77 virtual-stack-vars)
(const_int -8 [0xfffffffffffffff8])) [1 a+0 S4 A64])) "test.c":7:5 -1
(nil))
(insn 9 8 10 2 (set (reg:SI 4 si)
(reg:SI 86)) "test.c":7:5 -1
(nil))
(insn 10 9 11 2 (set (reg:SI 5 di)
(reg:SI 87)) "test.c":7:5 -1
(nil))
(call_insn 11 10 12 2 (set (reg:SI 0 ax)
(call (mem:QI (symbol_ref:DI ("xor") [flags 0x41] <function_decl 0x7f71eea05800 xor>) [0 xor S1 A8])
(const_int 0 [0]))) "test.c":7:5 -1
(nil)
(expr_list:SI (use (reg:SI 5 di))
(expr_list:SI (use (reg:SI 4 si))
(nil))))
(insn 12 11 13 2 (set (reg:SI 82 [ _1 ])
(reg:SI 0 ax)) "test.c":7:5 -1
(nil))
(insn 13 12 14 2 (set (reg:SI 88)
(mem/c:SI (plus:DI (reg/f:DI 77 virtual-stack-vars)
(const_int -4 [0xfffffffffffffffc])) [1 b+0 S4 A32])) "test.c":7:5 -1
(nil))
(insn 14 13 15 2 (set (reg:SI 89)
(mem/c:SI (plus:DI (reg/f:DI 77 virtual-stack-vars)
(const_int -8 [0xfffffffffffffff8])) [1 a+0 S4 A64])) "test.c":7:5 -1
(nil))
(insn 15 14 16 2 (set (reg:SI 4 si)
(reg:SI 88)) "test.c":7:5 -1
(nil))
(insn 16 15 17 2 (set (reg:SI 5 di)
(reg:SI 89)) "test.c":7:5 -1
(nil))
(call_insn 17 16 18 2 (set (reg:SI 0 ax)
(call (mem:QI (symbol_ref:DI ("add") [flags 0x41] <function_decl 0x7f71eea05700 add>) [0 add S1 A8])
(const_int 0 [0]))) "test.c":7:5 -1
(nil)
(expr_list:SI (use (reg:SI 5 di))
(expr_list:SI (use (reg:SI 4 si))
(nil))))
(insn 18 17 19 2 (set (reg:SI 83 [ _2 ])
(reg:SI 0 ax)) "test.c":7:5 -1
(nil))
(insn 19 18 20 2 (set (reg:SI 1 dx)
(reg:SI 82 [ _1 ])) "test.c":7:5 -1
(nil))
(insn 20 19 21 2 (set (reg:SI 4 si)
(reg:SI 83 [ _2 ])) "test.c":7:5 -1
(nil))
(insn 21 20 22 2 (set (reg:DI 90)
(symbol_ref/f:DI ("*.LC0") [flags 0x2] <var_decl 0x7f71eea09120 *.LC0>)) "test.c":7:5 -1
(nil))
(insn 22 21 23 2 (set (reg:DI 5 di)
(reg:DI 90)) "test.c":7:5 -1
(expr_list:REG_EQUAL (symbol_ref/f:DI ("*.LC0") [flags 0x2] <var_decl 0x7f71eea09120 *.LC0>)
(nil)))
(insn 23 22 24 2 (set (reg:QI 0 ax)
(const_int 0 [0])) "test.c":7:5 -1
(nil))
(call_insn 24 23 25 2 (set (reg:SI 0 ax)
(call (mem:QI (symbol_ref:DI ("printf") [flags 0x41] <function_decl 0x7f71ee920100 printf>) [0 __builtin_printf S1 A8])
(const_int 0 [0]))) "test.c":7:5 -1
(nil)
(expr_list (use (reg:QI 0 ax))
(expr_list:DI (use (reg:DI 5 di))
(expr_list:SI (use (reg:SI 4 si))
(expr_list:SI (use (reg:SI 1 dx))
(nil))))))
(insn 25 24 28 2 (set (reg:SI 84 [ _9 ])
(const_int 0 [0])) "<built-in>":0:0 -1
(nil))
(insn 28 25 32 2 (set (reg:SI 85 [ <retval> ])
(reg:SI 84 [ _9 ])) "<built-in>":0:0 -1
(nil))
(insn 32 28 33 2 (set (reg/i:SI 0 ax)
(reg:SI 85 [ <retval> ])) "test.c":8:1 -1
(nil))
(insn 33 32 0 2 (use (reg/i:SI 0 ax)) "test.c":8:1 -1
(nil))几乎看不懂了,不过能看到一些对寄存器和栈的操作
查看LLVM IR
clang -S -emit-llvm test.c -o test.ll
cat test.llIR如下:
; ModuleID = 'test.c'
source_filename = "test.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-pc-linux-gnu"
@.str = private unnamed_addr constant [14 x i8] c"a+b=%d,a^b=%x\00", align 1
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
store i32 2, i32* %1, align 4
store i32 3, i32* %2, align 4
%3 = load i32, i32* %1, align 4
%4 = load i32, i32* %2, align 4
%5 = call i32 @add(i32 noundef %3, i32 noundef %4)//调用 add(a, b),结果存到 %5
%6 = load i32, i32* %1, align 4
%7 = load i32, i32* %2, align 4
%8 = call i32 @xor(i32 noundef %6, i32 noundef %7)
%9 = call i32 (i8*, ...) @printf(i8* noundef getelementptr inbounds ([14 x i8], [14 x i8]* @.str, i64 0, i64 0), i32 noundef %5, i32 noundef %8)
ret i32 0
}
declare i32 @printf(i8* noundef, ...) #1
declare i32 @add(i32 noundef, i32 noundef) #1
declare i32 @xor(i32 noundef, i32 noundef) #1
attributes #0 = { noinline nounwind optnone uwtable "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
attributes #1 = { "frame-pointer"="all" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
!llvm.module.flags = !{!0, !1, !2, !3, !4}
!llvm.ident = !{!5}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 7, !"PIC Level", i32 2}
!2 = !{i32 7, !"PIE Level", i32 2}
!3 = !{i32 7, !"uwtable", i32 1}
!4 = !{i32 7, !"frame-pointer", i32 2}
!5 = !{!"Ubuntu clang version 14.0.0-1ubuntu1.1"}很晕,因为它比GIMPLE更接近汇编;不过编译器信息、逻辑还是能看一看(有点汇编的感觉)。
LLVM IR 是 SSA(静态单赋值) 形式的,所有变量只能赋值一次,所以
load很多
5 机器无关代码优化
在 GIMPLE 和 RTL阶段进行,
目的是在不考虑具体硬件架构的情况下,优化代码的逻辑结构,提高执行效率,减少不必要的计算和存储操作。

6. 目标代码生成
代码生成器将中间语言转换成线性的机器码序列,生成汇编代码,然后通过汇编器和链接器生成可执行文件
2.指令集架构(ISA)
汇编代码生成后,有许多种,除了常见的x86_64汇编,还有MIPS、ARM、RISC-V等,需要对它们加以区分,才能保证在逆向一个.s文件时明确指令集架构并且采取对应策略。
2.0 指令集架构分类
- **复杂指令集计算机(Complex Instruction Set Computer,CISC:)**每个指令可执行若干低端操作,例如存储器读取、存储、计算操作等,指令数目多且复杂,每条指令字长不相等。这些特性使得代码编写较为简单,但是复杂的指令需要若干指令周期才可以实现。
- 精简指令集计算机(Reduced Instruction Set Computer,RISC:)对指令数目与寻址方式都做了精简,只保留经常使用的指令,因此实现更加容易,指令并行程度较好,编译器效率较高。但是对于一些特殊操作,需要通过处理器额外的执行时间来弥补。其特征包括统一指令编码、泛用的寄存器,单纯的寻址模式等,每条指令的执行时间较短。
目前市场上主流的芯片架构有 X86、ARM、RISC-V和MIPS四种:
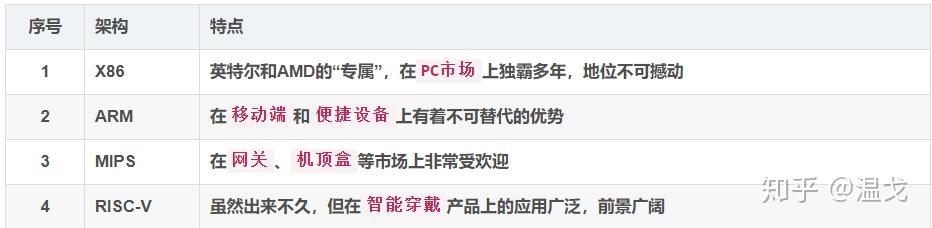
2.1 x86/x86-64
CISC架构,16位CPU(i8086)就是x86架构的,《汇编语言》(王爽)书里使用的指令集也是x86指令集,兼容16/32/64位。
使用gcc默认生成的就是x86汇编
以案例test.c生成的.s为例:
.file "test.c"
.text
.section .rodata
.LC0:
.string "a+b=%d,a^b=%x"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
pushq %rbx
subq $24, %rsp
.cfi_offset 3, -24
movl $2, -24(%rbp)
movl $3, -20(%rbp)
movl -20(%rbp), %edx
movl -24(%rbp), %eax
movl %edx, %esi
movl %eax, %edi
call xor@PLT
movl %eax, %ebx
movl -20(%rbp), %edx
movl -24(%rbp), %eax
movl %edx, %esi
movl %eax, %edi
call add@PLT
movl %ebx, %edx
movl %eax, %esi
leaq .LC0(%rip), %rax
movq %rax, %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
movq -8(%rbp), %rbx
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:2.2 ARM
RISC 架构
ARMv7(32 位),ARMv8(64 位,AArch64 模式)
2.3 MIPS(MIPS32 / MIPS64)
RISC 架构,固定长度指令(32 位)
2.4 RISC-V(RV32 / RV64)
RISC 开源架构,考虑小型、快速、低功耗的现实情况
3.本地编译与交叉编译
3.1 本地编译(Native Compilation)
本地编译可以理解为在当前编译平台(运行编译器的系统,包括操作系统和指令集架构)下编译出来的程序只能在相同架构的平台下运行
例如在x86指令集架构的windows下用VS2022写c代码,编译出来的程序就是x8体系的,至于是x86还是x86-64看具体使用的目标架构
3.2 交叉编译
交叉编译主要和嵌入式开发有关,由于嵌入式系统中的各种资源相对有限,只够嵌入式系统运行的,没太多剩余的资源,所以很难进行直接的本地编译。另外,在编译多个目标库时也会用到,例如在Windows中为底层构造完全不同的Linux编译程序;在电脑上为移动端操作系统构建程序。
交叉编译器(Cross compiler)/交叉编译工具链,是一套用于 在一个平台上编译出可在另一个平台上运行的代码 的工具集。
命名特点:arch-vender-os-abi <目标架构>-<供应商>-<操作系统>-
arm-linux-gnueabi-gcc
ARM32位架构,Linux操作系统,使用 GNU EABI,GCC编译器以ISCTF2024的一道MIPS逆向为例:
给了一个mips.s文件,看文件头确认是MIPS32位架构
本地电脑是x86_64架构的,使用交叉编译工具链编译它
#MIPS架构,Linux,GNU工具链,GAS汇编器
mips-linux-gnu-as -o mips.o mips.s#汇编
mips-linux-gnu-ld -o mips mips.o#生成可执行文件如果报错标准库(libc)没有自动包含可使用
mips-linux-gnu-gcc -o mips mips.o -static # 直接用 gcc 进行生成可执行文件后就可以拿去用ida分析
4. 总结
从 .c 源代码到可执行文件,需要经过 预处理、编译、汇编、链接 四个主要阶段。其中,编译 过程可进一步分为 前端、优化、后端 三个部分(某些编译器可能将优化并入前端和后端,形成前端优化和后端优化)。
- 前端负责 词法分析、语法分析、语义分析,并将源代码转换为 中间表示(IR, Intermediate Representation),同时进行部分优化(如常量折叠、死代码消除)。
- 优化阶段对 IR 进行 中立于目标架构的优化(如循环优化、寄存器分配、指令调度),以提高代码执行效率。
- 后端负责将优化后的 IR 转换为目标机器的汇编代码或机器代码,并可能进行进一步的架构相关优化(如指令选择、指令调度)。
最终,汇编器将汇编代码转换为机器代码,而链接器负责解析符号、处理库依赖,生成最终的可执行文件。
由于 编译器、操作系统、指令集架构 的不同,相同的 C 代码可能生成不同的汇编代码。如果需要在一个平台(如 x86 架构)下编译适用于另一个平台(如 MIPS 架构)的程序,需要使用 交叉编译工具链
参考资料:
维基百科:https://zh.wikipedia.org/↗
编译原理与技术(一)——编译器的整体结构_编译器架构-CSDN博客↗
X86、ARM、RISC-V,MIPS傻傻分不清楚?一文带你看懂! - 知乎↗
交叉编译&本地编译的区别_简述交叉编译器和普通编译器的本质区别是什么-CSDN博客↗