
WP
WARMUP
解压后是一个vbs文件,火绒直接杀了,下播。
文件后缀改成txt,打开发现
包含了一行VBScript/VBA代码,主要结构是:
Execute(chr(计算表达式) & chr(计算表达式) & ... & vbcrlf)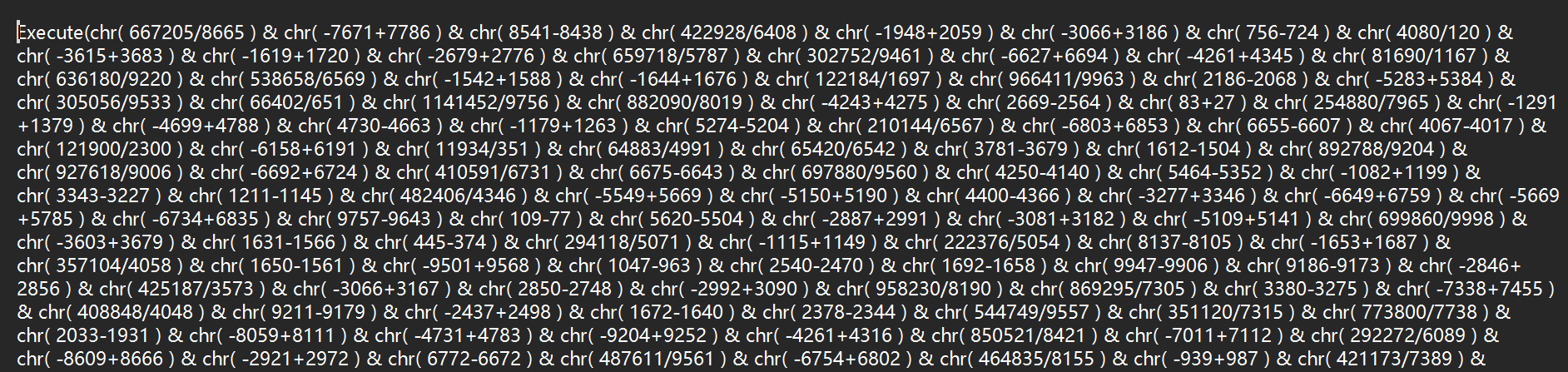
执行原理
- 先计算所有chr()函数中的数学表达式
- 将计算结果作为ASCII码转换为字符
- 将所有字符拼接成一个字符串
- 用Execute执行这个拼接后的字符串
用脚本提取:
import re
import math
def decode_chr_expressions(file_path):
# 打开文件并读取内容
with open(file_path, 'r', encoding='utf-8') as file:
code = file.read()
# 提取所有chr()中的表达式
expressions = re.findall(r'chr\(\s*([^)]+)\s*\)', code)
# 计算每个表达式并转换为字符
result = []
for expr in expressions:
try:
# 计算表达式(使用eval有安全风险,仅用于分析已知代码)
value = eval(expr)
# 取整并确保在ASCII范围内
char = chr(int(round(value)))
result.append(char)
except:
result.append(f"[Error:{expr}]")
# 拼接结果
decoded_string = ''.join(result)
# 将解码结果写入新文件
output_path = file_path.replace('.txt', '_decoded.txt')
with open(output_path, 'w', encoding='utf-8') as output_file:
output_file.write(decoded_string)
print(f"解码完成,结果已保存到: {output_path}")
return decoded_string
# 使用示例
if __name__ == "__main__":
file_path = "chal.txt" # 替换为你的文件路径
decoded = decode_chr_expressions(file_path)
print("\n解码结果预览(前200个字符):")
print(decoded[:200])转换成代码后发现是RC4,key和cipher都知道

exp:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define KEY_LENGTH 256
// RC4 密钥调度算法(KSA)
void rc4_init(unsigned char *s, unsigned char *key, int key_length) {
int i, j = 0;
unsigned char temp;
for (i = 0; i < KEY_LENGTH; i++) {
s[i] = i;
}
for (i = 0; i < KEY_LENGTH; i++) {
j = (j + s[i] + key[i % key_length]) % KEY_LENGTH;
temp = s[i];
s[i] = s[j];
s[j] = temp;
}
}
// RC4 伪随机生成算法(PRGA)
void rc4_crypt(unsigned char *s, unsigned char *data, int data_length) {
int i = 0, j = 0, k;
unsigned char temp;
for (k = 0; k < data_length; k++) {
i = (i + 1) % KEY_LENGTH;
j = (j + s[i]) % KEY_LENGTH;
temp = s[i];
s[i] = s[j];
s[j] = temp;
data[k] ^= s[(s[i] + s[j]) % KEY_LENGTH];
}
}
// 将十六进制字符串转换为字节数组
void hex_to_bytes(const char *hex, unsigned char *bytes, int length) {
for (int i = 0; i < length; i++) {
sscanf(hex + 2 * i, "%2hhx", &bytes[i]);
}
}
int main() {
unsigned char key[] = "rc4key";
char hex_data[] = "90df4407ee093d309098d85a42be57a2979f1e51463a31e8d15e2fac4e84ea0df622a55c4ddfb535ef3e51e8b2528b826d5347e165912e99118333151273cc3fa8b2b3b413cf2bdb1e8c9c52865efc095a8dd89b3b3cfbb200bbadbf4a6cd4";
int data_length = strlen(hex_data) / 2;
unsigned char *data = (unsigned char *)malloc(data_length);
unsigned char s[KEY_LENGTH];
// 将十六进制字符串转换为字节数组
hex_to_bytes(hex_data, data, data_length);
// 初始化 RC4 密钥调度
rc4_init(s, key, strlen((char *)key));
// 进行 RC4 解密
rc4_crypt(s, data, data_length);
// 输出解密结果
printf("Decrypted: %s\n", data);
free(data);
return 0;
}Decrypted: flag{We1c0me_t0_XYCTF_2025_reverse_ch@lleng3_by_th3_w@y_p3cd0wn's_chall_is_r3@lly_gr3@t_&_fuN!}****
Moon
给了moon.pyd和main.py文件
通过导入自定义的moon库使用其中的函数
尝试过用ida分析,但没什么经验,寸步难行
问的GPT,思路很清晰,学习一下
首先用help(moon)获取基本信息
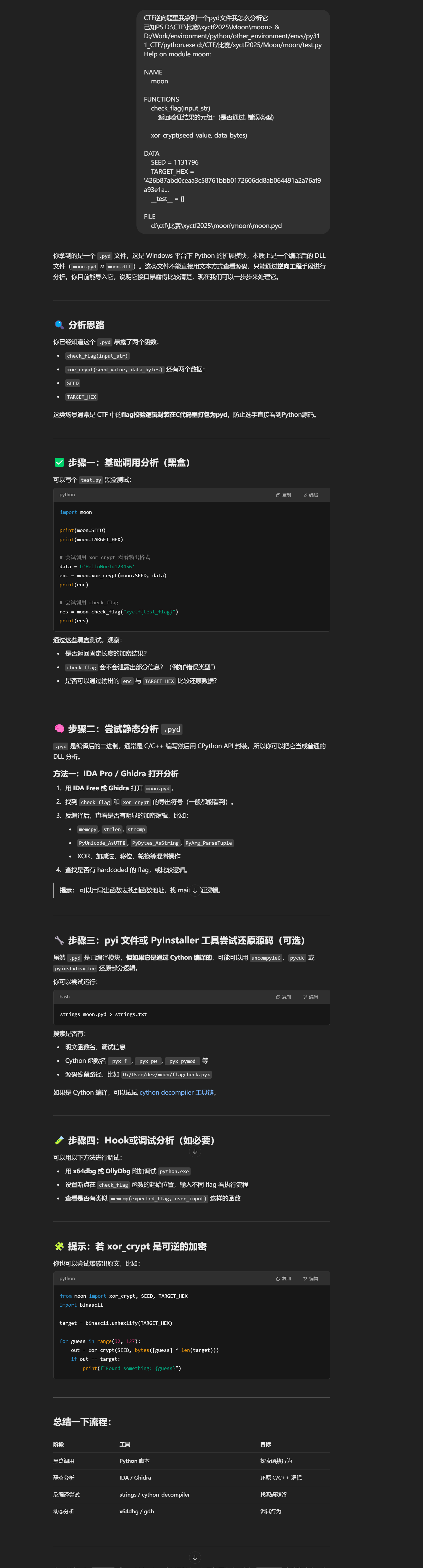
可能是对称加密,尝试一下把密文作为输入进行加密然后输出
from moon import xor_crypt, SEED, TARGET_HEX
import binascii
target_bytes = binascii.unhexlify(TARGET_HEX)
flag_bytes = xor_crypt(SEED, target_bytes)
print("还原 flag:", flag_bytes)
print("尝试解码:", flag_bytes.decode(errors="ignore"))
'''
还原 flag: b'flag{but_y0u_l00k3d_up_@t_th3_mOOn}'
尝试解码: flag{but_y0u_l00k3d_up_@t_th3_mOOn}
'''****
Dragon
给了一个Dragon.bc文件,正好前段时间初步较为系统地学了一下编译的整个过程
LLVM 字节码文件
类型:编译器中间代码
产生方式:由 Clang/LLVM 编译器生成
特点:
- 包含平台无关的中间表示(IR)
- 可用于交叉编译和链接时优化
- 通常由
clang -emit-llvm 命令生成
clang -c -emit-llvm example.c -o example.bc
llvm-dis example.bc # 反汇编为可读的LLVM IR那么只需要继续用clang把它编译成可执行文件就能拖ida分析
编译过程中踩了很多坑,一开始以为是Linux下的,下llvm clang后编译发现版本过低,好不容易把版本解决了又发现是windows下编译的。随后尝试用VS2022内置的clang来编译,各种报错。最后选择去github上找了个clang+llvm-20.1.2-x86_64-pc-windows-msvc项目才解决
编译后拖ida分析
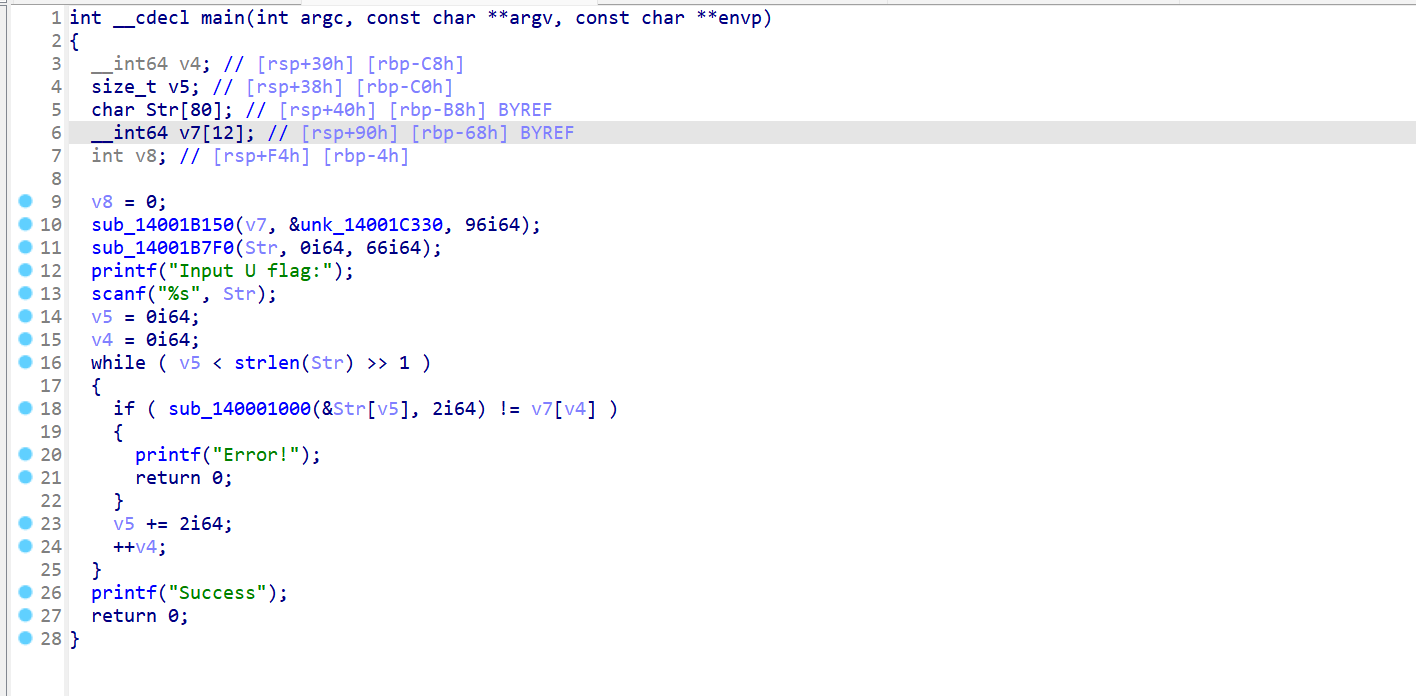
逻辑很清晰,主要看sub_140001000函数
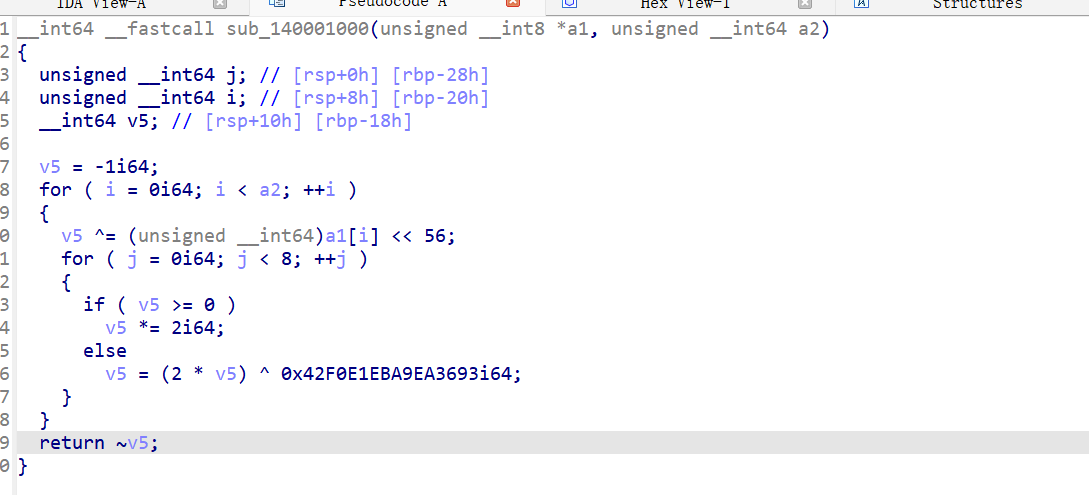
是一个魔改的CRC64校验,需要爆破一下,注意传进来的a2=2
#include <stdio.h>
#include <stdint.h>
uint64_t custom_crc64(const uint8_t *a1, uint64_t a2) {
uint64_t v5 = ~0ULL;
uint64_t i, j;
for (i = 0; i < a2; ++i) {
v5 ^= (uint64_t)a1[i] << 56;
for (j = 0; j < 8; ++j) {
if ((int64_t)v5 >= 0)
v5 <<= 1;
else
v5 = (v5 << 1) ^ 0x42F0E1EBA9EA3693ULL;
}
}
return ~v5;
}
int main() {
uint8_t input[2];
uint64_t target_crc[12] = {
0xDC63E34E419F7B47, 0x031EF8D4E7B2BFC6, 0x12D62FBC625FD89E, 0x83E8B6E1CC5755E8,
0xFC7BB1EB2AB665CC, 0x9382CA1B2A62D96B, 0xB1FFF8A07673C387, 0x0DA81627388E05E1,
0x9EF1E61AE8D0AAB7, 0x92783FD2E7F26145, 0x63C97CA1F56FE60B, 0x9BD3A8B043B73AAB
}; // <<< 替换为你的CRC返回值
for(int j=0;j<12;j++){
for (uint32_t i = 0; i <= 0xFFFF; ++i) {
input[0] = (i >> 8) & 0xFF;
input[1] = i & 0xFF;
if (custom_crc64(input, 2) == target_crc[j]) {
printf("%c%c", input[0], input[1]);
break;
}
}
}
return 0;
}
//flag{LLVM_1s_Fun_Ri9h7?}****
Lake
一直以为自己还有哪里没发现,结果是附件多解,呜呜呜吃个饭回来没血了
PE64文件,Pascal语言?不懂有没有大佬解释一下

直接走动调,从这里找到主逻辑

很长,就截一部分,前面主要是在打印信息,好像是走一遍循环打印一个字符,

直接来到获取输入的地方
随便输点进去,往后走,修改一下名字
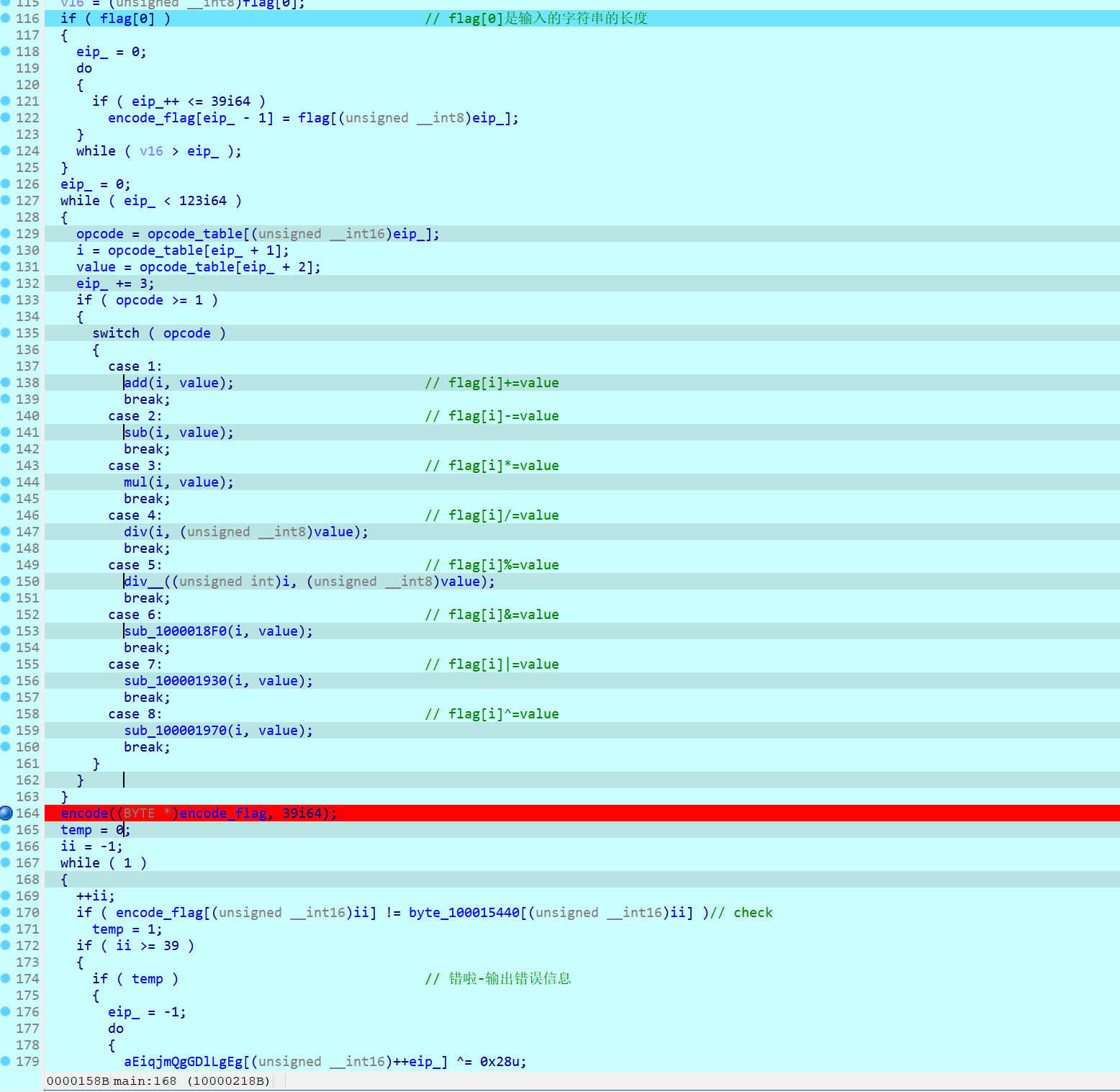
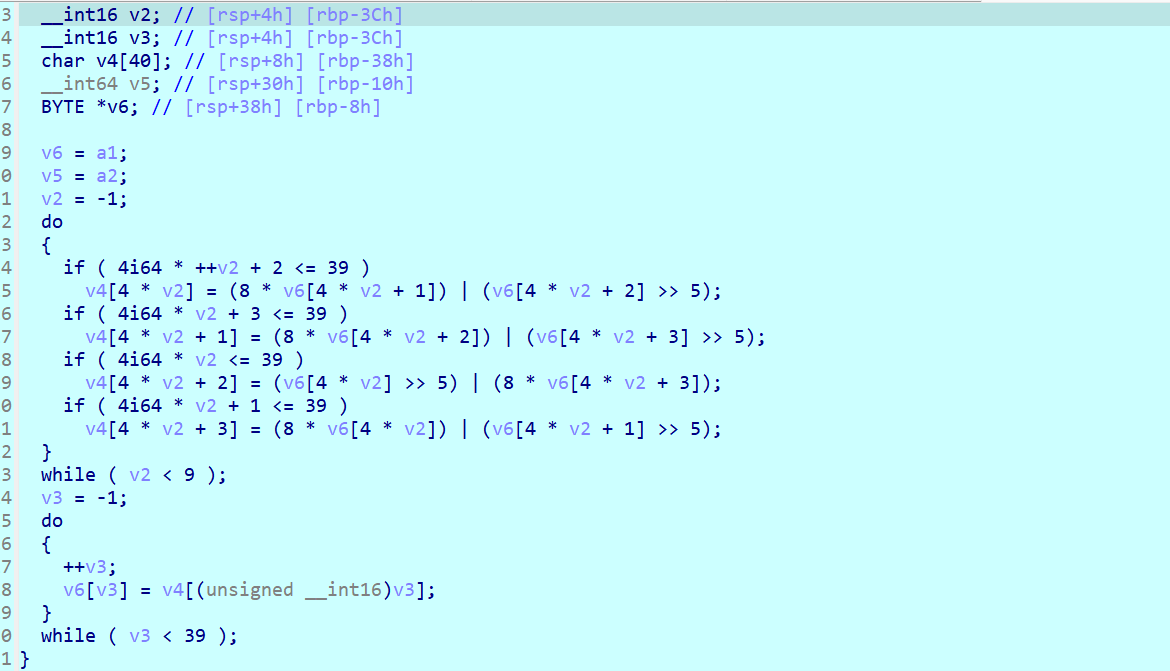
逻辑很清晰,第一步先通过操作码解析对flag进行加密,第二步再进行移位加密
exp1:
#include<stdio.h>
unsigned short opcode_tab[123] = {
0x0002, 0x0002, 0x000C, 0x0001, 0x001A, 0x0055, 0x0001, 0x0023,
0x000C, 0x0002, 0x000E, 0x0009, 0x0001, 0x001B, 0x0006, 0x0008,
0x0006, 0x0005, 0x0008, 0x0001, 0x0005, 0x0002, 0x001B, 0x000E,
0x0002, 0x0019, 0x0003, 0x0002, 0x001A, 0x0004, 0x0008, 0x0004,
0x0008, 0x0001, 0x0003, 0x000C, 0x0002, 0x000C, 0x000A, 0x0001,
0x0025, 0x0002, 0x0001, 0x0020, 0x0002, 0x0001, 0x0009, 0x000C,
0x0008, 0x001A, 0x0005, 0x0002, 0x0004, 0x000D, 0x0008, 0x0008,
0x000F, 0x0002, 0x000A, 0x000E, 0x0001, 0x0010, 0x0007, 0x0001,
0x000C, 0x0007, 0x0008, 0x0022, 0x0008, 0x0008, 0x0015, 0x000A,
0x0001, 0x0027, 0x007E, 0x0002, 0x0007, 0x0002, 0x0008, 0x000F,
0x0003, 0x0008, 0x000A, 0x000A, 0x0001, 0x0022, 0x000B, 0x0002,
0x0012, 0x0008, 0x0002, 0x0019, 0x0009, 0x0008, 0x000E, 0x0006,
0x0008, 0x0000, 0x0005, 0x0001, 0x000A, 0x0008, 0x0008, 0x001B,
0x0007, 0x0008, 0x000D, 0x0006, 0x0008, 0x000D, 0x0004, 0x0008,
0x0017, 0x000C, 0x0008, 0x0022, 0x000E, 0x0002, 0x0012, 0x0034,
0x0001, 0x0026, 0x0077,
};
int main(){
int eip=0;
int opcode;
int i=0;
int value=0;
while(eip<123){
opcode=opcode_tab[eip];
i = opcode_tab[eip + 1];
value = opcode_tab[eip + 2];
eip+=3;
if(opcode>=1){
switch (opcode) {
case 1://加
printf("flag[%d]+=%d;\n",i,value);
break;
case 2://减
printf("flag[%d]-=%d;\n",i,value);
break;
case 3://乘
printf("flag[%d]*=%d;\n",i,value);
break;
case 4://除
printf("flag[%d]/=%d;\n",i,value);
break;
case 5://取余
printf("flag[%d]%%=%d;\n",i,value);
break;
case 6://取&
printf("flag[%d]&=%d;\n",i,value);
break;
case 7://取|
printf("flag[%d]|=%d;\n",i,value);
break;
case 8://异或
printf("flag[%d]^=%d;\n",i,value);
break;
default://加
printf("error\n");
break;
}
}
}
return 0;
}
/*
flag[2]-=12
flag[26]+=85
flag[35]+=12
flag[14]-=9
flag[27]+=6
flag[6]^=5
flag[1]^=5
flag[27]-=14
flag[25]-=3
flag[26]-=4
flag[4]^=8
flag[3]+=12
flag[12]-=10
flag[37]+=2
flag[32]+=2
flag[9]+=12
flag[26]^=5
flag[4]-=13
flag[8]^=15
flag[10]-=14
flag[16]+=7
flag[12]+=7
flag[34]^=8
flag[21]^=10
flag[39]+=126
flag[7]-=2
flag[15]^=3
flag[10]^=10
flag[34]+=11
flag[18]-=8
flag[25]-=9
flag[14]^=6
flag[0]^=5
flag[10]+=8
flag[27]^=7
flag[13]^=6
flag[13]^=4
flag[23]^=12
flag[34]^=14
flag[18]-=52
flag[38]+=119
*/exp2:
#include <stdio.h>
#include <ctype.h>
#include <stdint.h>
#include<stdlib.h>
void decode(uint8_t *a1) {
uint8_t tmp[40];
memcpy(tmp, a1, 40); // 复制密文内容
for (int i = 0; i < 10; i++) {
int idx = 4 * i;
uint8_t E = tmp[idx + 0];
uint8_t F = tmp[idx + 1];
uint8_t G = tmp[idx + 2];
uint8_t H = tmp[idx + 3];
// 反推回原来的 A, B, C, D
uint8_t A = ((G & 0x07) << 5) | ((H >> 3) & 0x1F);
uint8_t B = ((E >> 3) & 0x1F) | ((H & 0x07) << 5);
uint8_t C = ((E & 0x07) << 5) | ((F >> 3) & 0x1F);
uint8_t D = ((F & 0x07) << 5) | ((G >> 3) & 0x1F);
a1[idx + 0] = A;
a1[idx + 1] = B;
a1[idx + 2] = C;
a1[idx + 3] = D;
}
}
int main() {
unsigned char enc[40] = {
0x4A, 0xAB, 0x9B, 0x1B, 0x61, 0xB1, 0xF3, 0x32,
0xD1, 0x8B, 0x73, 0xEB, 0xE9, 0x73, 0x6B, 0x22,
0x81, 0x83, 0x23, 0x31, 0xCB, 0x1B, 0x22, 0xFB,
0x25, 0xC2, 0x81, 0x81, 0x73, 0x22, 0xFA, 0x03,
0x9C, 0x4B, 0x5B, 0x49, 0x97, 0x87, 0xDB, 0x51,
};
decode(enc);
printf("还原后的十六进制:\n");
for (int i = 0; i < 40; ++i) {
printf("0x%02X,", enc[i]);
}
printf("\n");
return 0;
}
/*
0x63,0x69,0x55,0x73,0x66,0x4C,0x36,0x3E,0x7D,0x7A,0x31,0x6E,0x64,
0x5D,0x2E,0x6D,0x66,0x30,0x30,0x64,0x5F,0x79,0x63,0x64,0x30,0x24,
0xB8,0x50,0x40,0x6E,0x64,0x5F,0x69,0x33,0x89,0x6B,0x6A,0x32,0xF0,
0xFB,
*/exp3:
#include <stdio.h>
void en(unsigned char*flag){
flag[2]-=12;
flag[26]+=85;
flag[35]+=12;
flag[14]-=9;
flag[27]+=6;
flag[6]^=5;
flag[1]^=5;
flag[27]-=14;
flag[25]-=3;
flag[26]-=4;
flag[4]^=8;
flag[3]+=12;
flag[12]-=10;
flag[37]+=2;
flag[32]+=2;
flag[9]+=12;
flag[26]^=5;
flag[4]-=13;
flag[8]^=15;
flag[10]-=14;
flag[16]+=7;
flag[12]+=7;
flag[34]^=8;
flag[21]^=10;
flag[39]+=126;
flag[7]-=2;
flag[15]^=3;
flag[10]^=10;
flag[34]+=11;
flag[18]-=8;
flag[25]-=9;
flag[14]^=6;
flag[0]^=5;
flag[27]^=7;
flag[13]^=6;
flag[13]^=4;
flag[23]^=12;
flag[34]^=14;
flag[18]-=52;
flag[38]+=119;
}
void de(unsigned char*flag){
flag[38] -= 119;
flag[18] += 52;
flag[34] ^= 14;
flag[23] ^= 12;
flag[13] ^= 4;
flag[13] ^= 6;
flag[27] ^= 7;
flag[10] -= 8;
flag[0] ^= 5;
flag[14] ^= 6;
flag[25] += 9;
flag[18] += 8;
flag[34] -= 11;
flag[10] ^= 10;
flag[15] ^= 3;
flag[7] += 2;
flag[39] -= 126;
flag[21] ^= 10;
flag[34] ^= 8;
flag[12] -= 7;
flag[16] -= 7;
flag[10] += 14;
flag[8] ^= 15;
flag[4] += 13;
flag[26] ^= 5;
flag[9] -= 12;
flag[32] -= 2;
flag[37] -= 2;
flag[12] += 10;
flag[3] -= 12;
flag[4] ^= 8;
flag[25] += 3;
flag[27] += 14;
flag[6] ^= 5;
flag[1] ^= 5;
flag[27] -= 6;
flag[26] += 4;
flag[14] += 9;
flag[35] -= 12;
flag[26] -= 85;
flag[2] += 12;
}
int main() {
unsigned char flag[40] = {
0x63,0x69,0x55,0x73,0x66,0x4C,0x36,0x3E,0x7D,0x7A,0x31,0x6E,0x64,0x5D,0x2E,0x6D,0x66,0x30,0x30,0x64,0x5F,0x79,0x63,0x64,0x30,0x24,0xB8,0x50,0x40,0x6E,0x64,0x5F,0x69,0x33,0x89,0x6B,0x6A,0x32,0xF0,0xFB};
de(flag);
for (int i = 0; i < 40; i++) {
printf("%c", flag[i]);
}
return 0;
}
//flag{L3@rn1ng_1n_0ld_sch00l_@nd_g3t_j0y}****
会飞的雷克萨斯

社工题
先搜事件
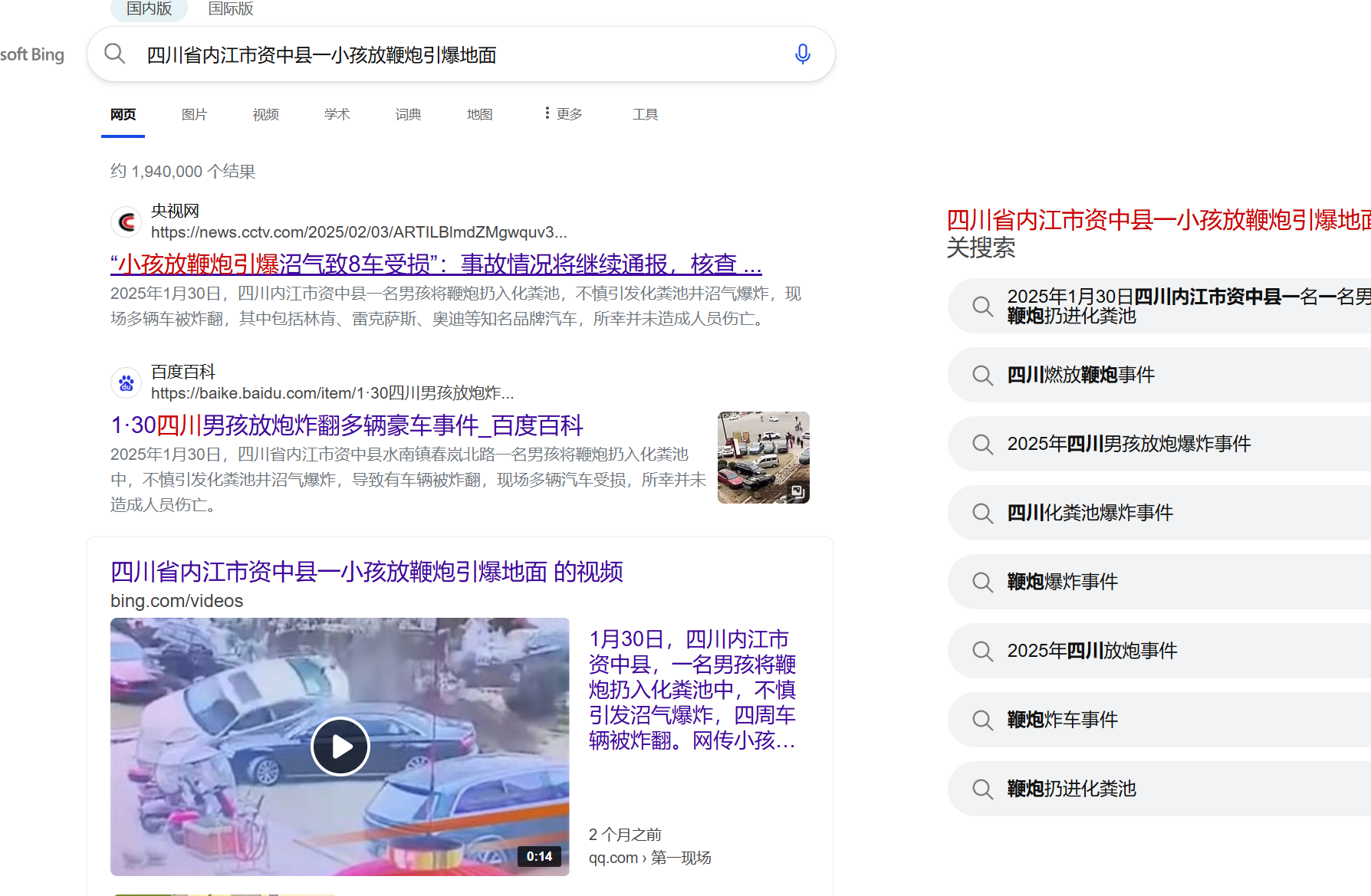
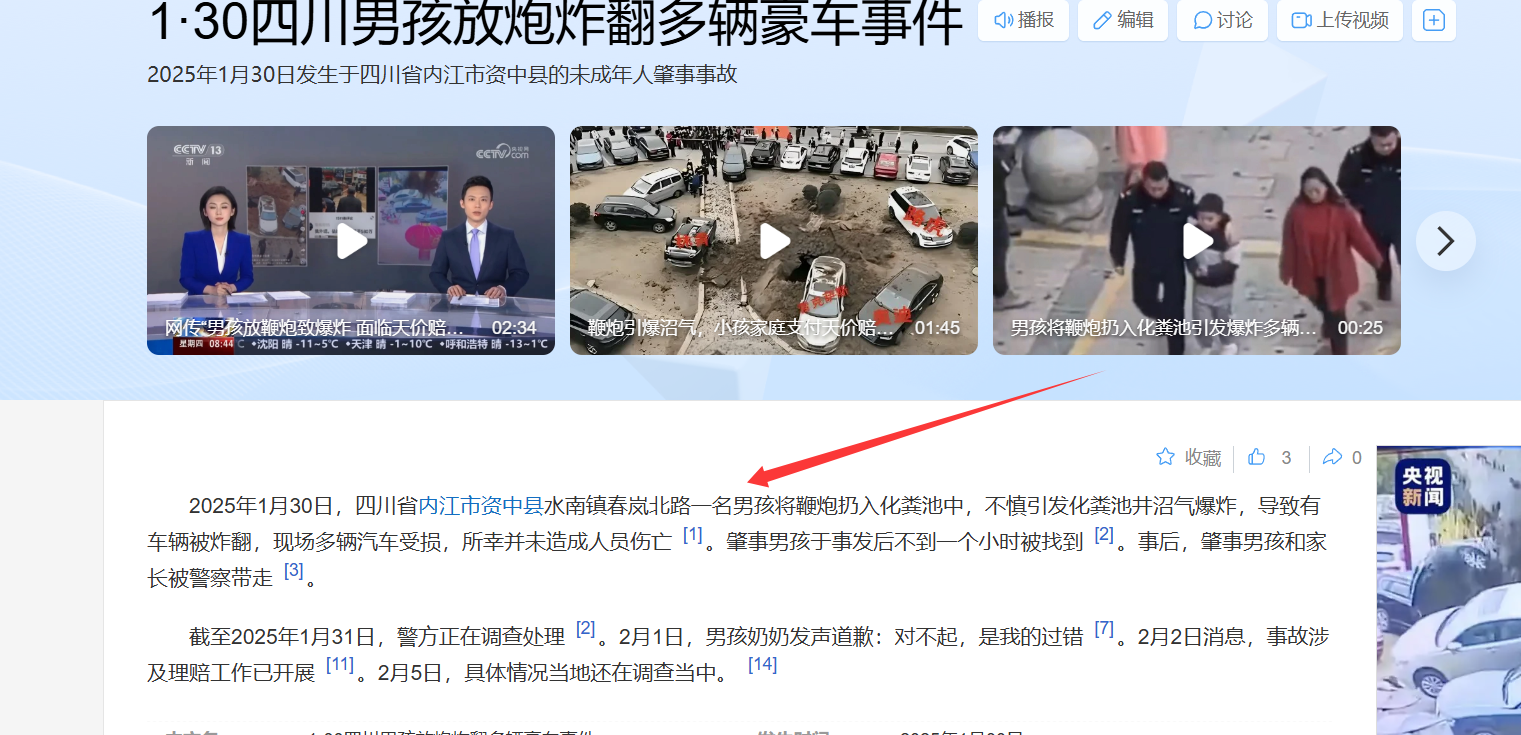
题目说一个x代表一个字,那就是最后有6个字,刚好和中铁城市中心对上
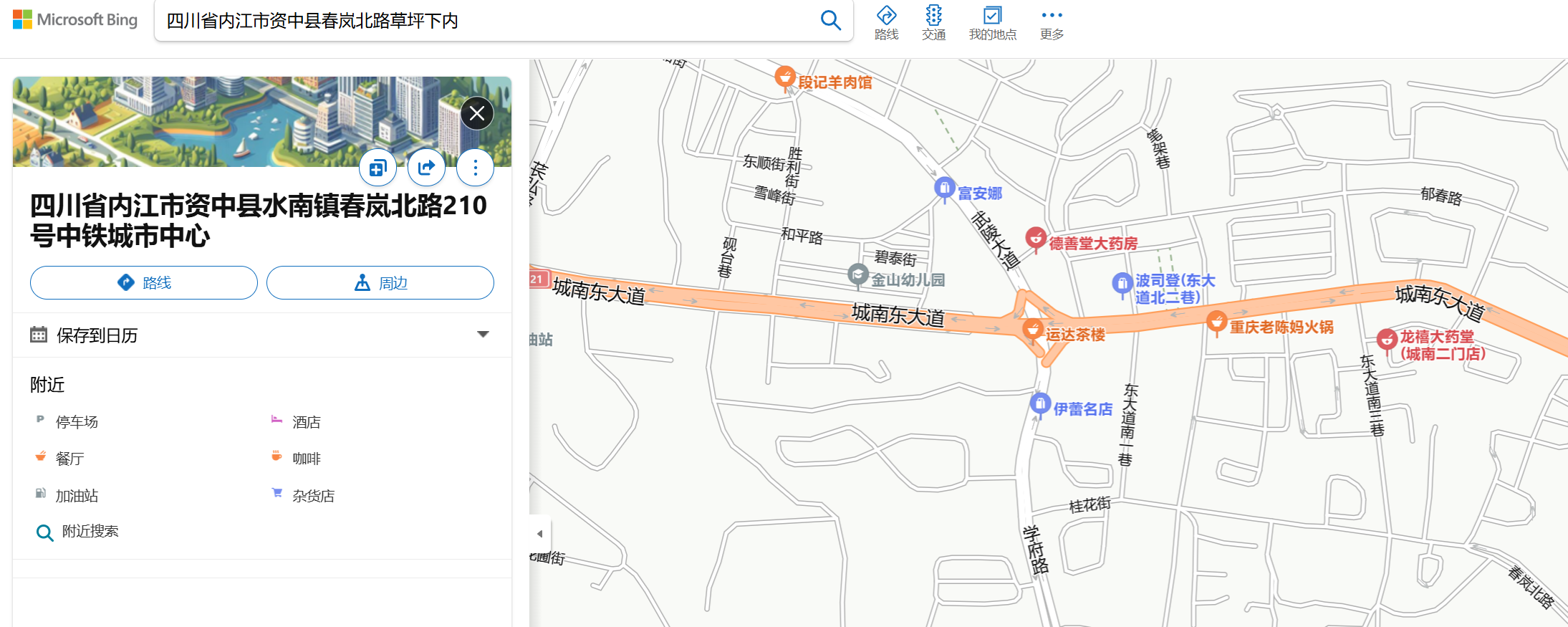
flag{四川省内江市资中县春岚北路中铁城市中心内}****
XGCTF

找到博客网址https://dragonkeeep.top/↗
找别人的WP,猜测里面会有对这件事的评价emmm

确定了赛题,看博客评论确实是来对了
查看源代码,找到了base64编码后的flag

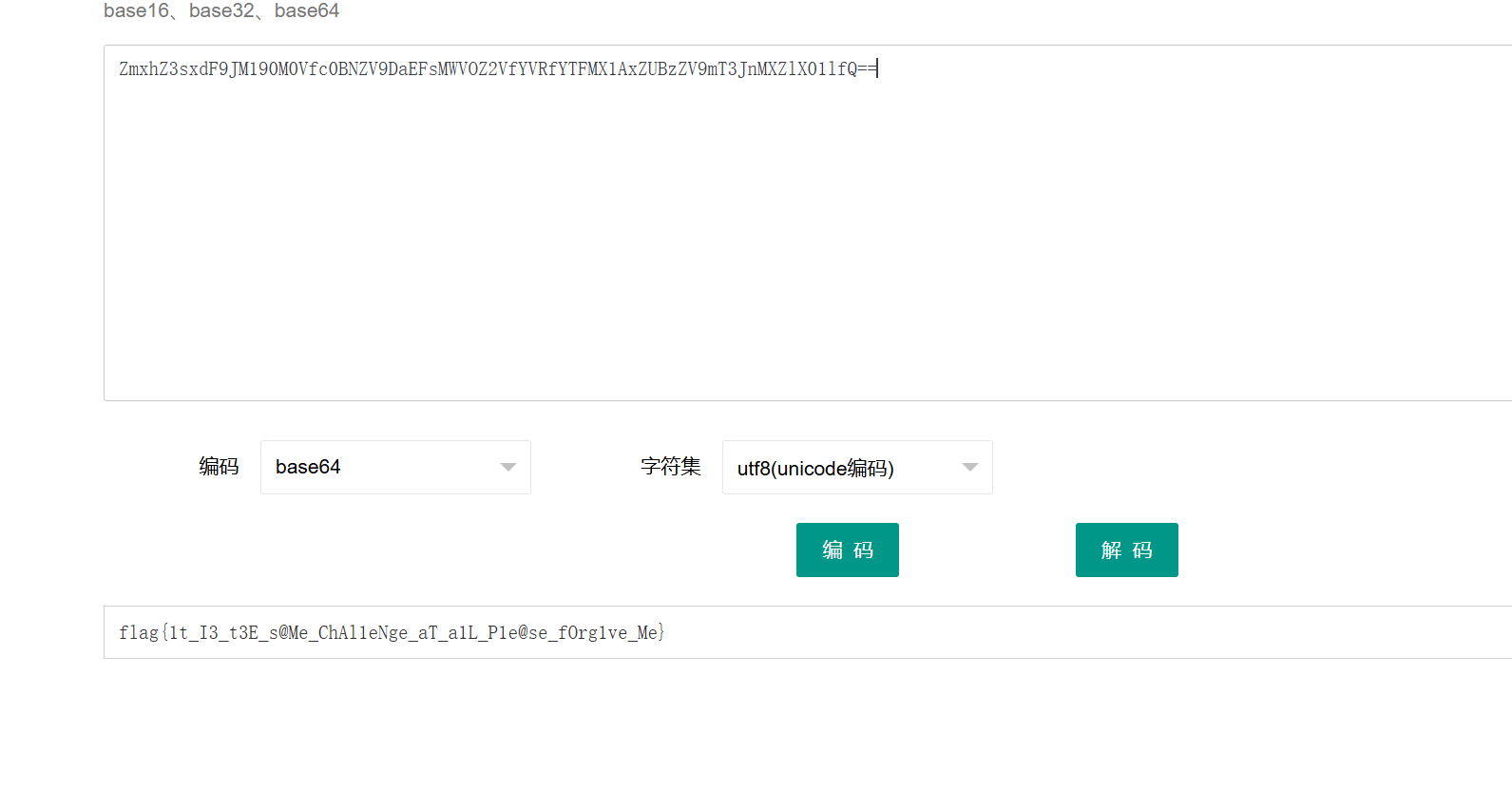
flag{1t_I3_t3E_s@Me_ChAl1eNge_aT_a1L_P1e@se_fOrg1ve_Me}
复现笔记
CrackMe
补基础知识:
GetDlgItemTextA
GetDlgItemTextA 是 Windows API 中的一个重要函数,用于从对话框控件中获取文本内容。
函数原型
UINT GetDlgItemTextA(
HWND hDlg, // 对话框句柄
int nIDDlgItem, // 控件ID
LPSTR lpString, // 接收文本的缓冲区
int cchMax // 缓冲区最大字符数
);参数说明
hDlg
- 类型:
HWND - 包含控件的对话框的句柄
- 类型:
nIDDlgItem
- 类型:
int - 要获取文本的控件的标识符(ID)
- 类型:
lpString
- 类型:
LPSTR (char 指针) - 接收文本的缓冲区指针
- 类型:
cchMax
- 类型:
int - 缓冲区可以存储的最大字符数(包括结尾的null字符)
- 类型:
返回值
- 成功:返回复制到缓冲区的字符数(不包括结尾的null字符)
- 失败:返回0
功能说明
- 该函数从指定的对话框控件中检索文本内容
- 对于编辑框(Edit)、静态文本(Static)、按钮(Button)等控件有效
- ANSI版本(
GetDlgItemTextA)处理多字节字符集(MBCS) - 对应的Unicode版本是
GetDlgItemTextW
IDA创建结构体
方法一:在IDA中打开Structures,快捷键是shifr+ F9 ,然后按insert键,进行插入。
方法二:shift+f1
CRC
IDEA算法
国际数据加密算法(IDEA)简介_idea算法-CSDN博客↗
IDEA(International Data Encryption Algorithm)算法最显著的特征包括以下几点,它们共同构成了 IDEA 的核心辨识特征:
1. 使用 3 种不同的代数运算
这是 IDEA 最具特色的设计,它结合了三种相互不兼容的代数结构,以增加加密的复杂性和安全性:
| 操作类型 | 模数 | 操作说明 |
|---|---|---|
| 模乘 | mod65537 | 在 GF(65537) 上的乘法,特殊处理 0 值为 65536 |
| 模加 | mod2^16 (65536) | 16 位无符号整数加法 |
| 按位异或 | bitwise XOR | 16 位操作,作为混合手段 |
👉 正是这三种运算的混合使用,使得 IDEA 能有效抵抗差分分析、线性分析等攻击方式。
2. 8 轮 + 1 次输出转换(Half-round)
IDEA 总共执行 8 轮加密轮变换 + 1 次输出变换,每一轮使用 6 个子密钥,最后使用 4 个子密钥进行输出变换。
3. 模 65537 的乘法操作特殊处理 0
在 GF(65537) 中,元素范围是 1~65536,而 IDEA 使用 0x0000 表示 65536,这意味着:
0 在 IDEA 中不是真正的 0,而是代表65536- IDEA 在实现中使用特殊方式避免 0 出现在乘法中(你的代码中也体现了)
例子:
(x == 0 ? 65536 : x) * (y == 0 ? 65536 : y) mod 655374. 使用 128 位密钥,输入输出为 64 位块
- 输入块:64 bits(分为四个 16-bit 的子块)
- 密钥:128 bits(生成 52 个子密钥,每个 16-bit)
- 子密钥用于每一轮的加、乘、异或操作
5. 结构对称、支持加解密
IDEA 的加解密过程非常对称,只需反转密钥顺序并计算解密子密钥即可进行解密,这使它非常适合硬件和软件实现。
总结:IDEA 的最显著特征是 ⬇️
三种代数运算混合(模65537乘法、模65536加法、按位异或)用于构造混淆与扩散,增强密码强度与抗攻击性。
整体逻辑
通过一个永真循环获取用户输入、执行逻辑处理、窗口建立、刷新以及弹窗提示
对flag的
6-12位做CRC+简单加密并验证检查flag的
前五位是否为"flag{"检查flag的第29位是否为
'}'使用PEB的标志位来检测调试状态(反调试)
通过
CRC生成IDEA算法的128位密钥,对flag的第13-28位共16字节数据进行IDEA算法加密并验证
复现
函数表里找到TLS回调函数
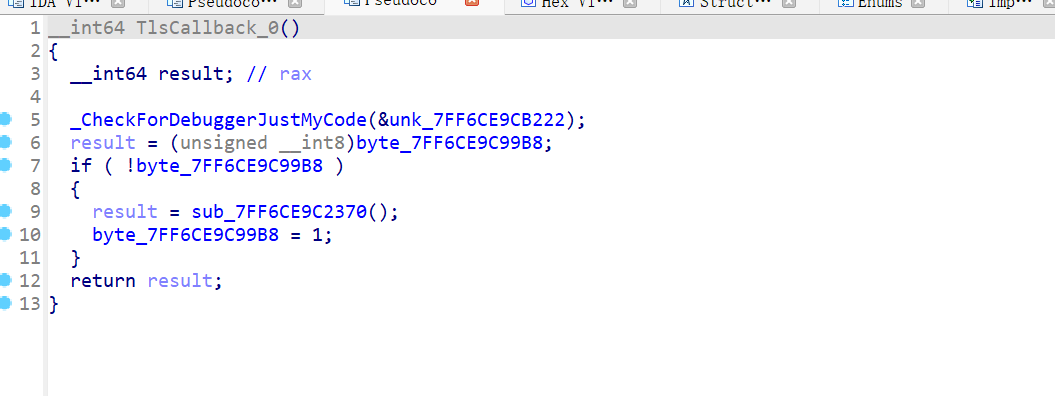
跟进sub_7FF6CE9C2370()
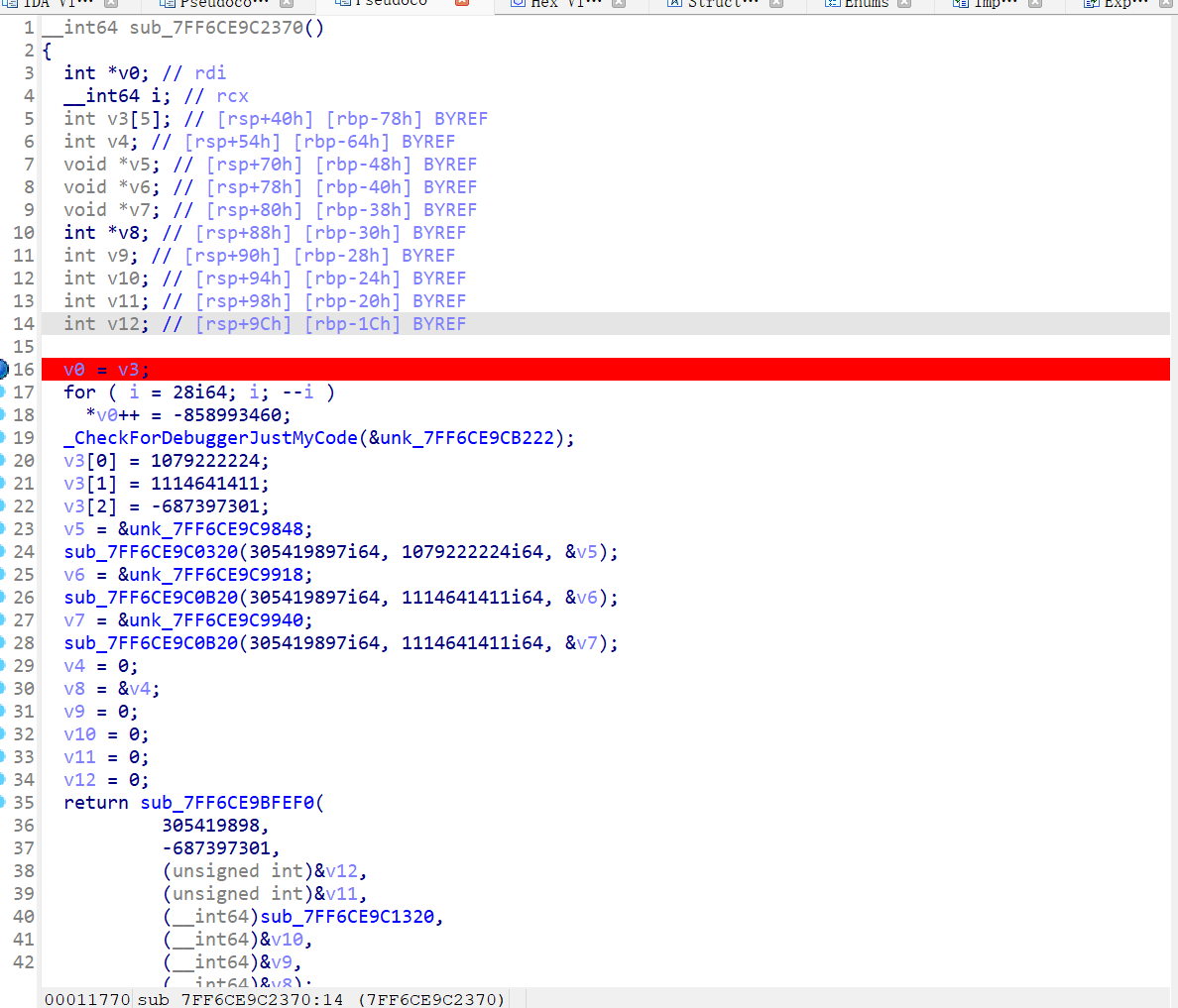
在这里看到很多形如sub_7FF6CE9C0320(305419897i64, 1079222224i64, &v5);的函数,随便点一个进去看
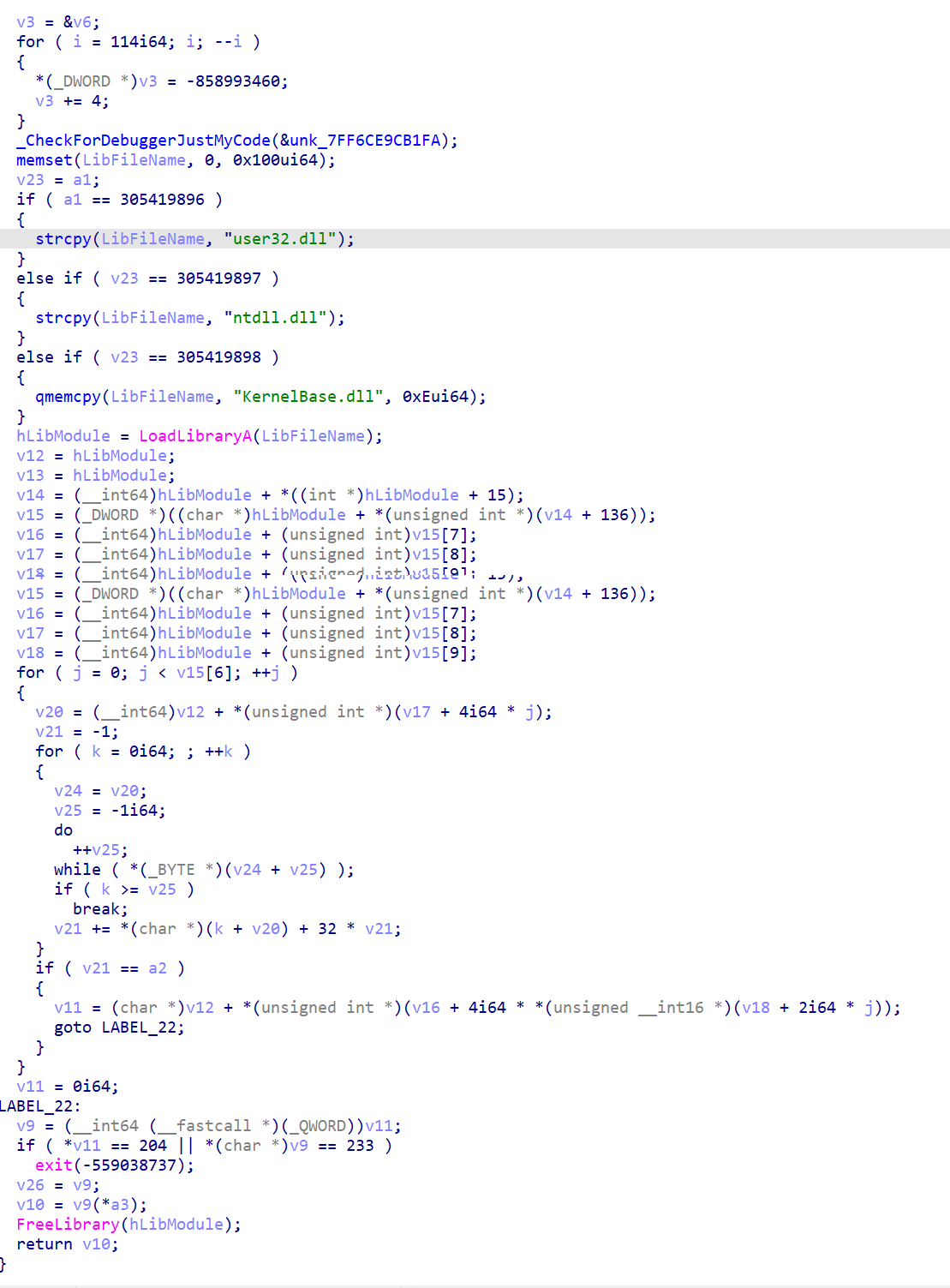
其实是一个动态加载DLL并获取函数地址进行调用的实现。主要是a1和a2,a1确定调用哪个dll,a2确定具体调用哪个函数。
下面是AI的理解:
使用
LoadLibraryA加载选定的DLLPE解析:
获取DLL的PE头信息
解析导出表(Export Table)相关地址:
v14: PE头偏移v15: 导出表指针v16: 导出函数地址表v17: 导出名称指针表v18: 导出序号表函数查找:
- 遍历导出表中的所有函数名
- 对每个函数名计算哈希值(通过特定算法)
- 将计算出的哈希值与传入的
a2比较,找到匹配的函数函数调用:
- 找到匹配函数后获取其地址
- 检查函数前导字节(防止被挂钩)
- 调用找到的函数,传入
a3指向的参数- 最后释放DLL
贴一个根据a1、a2手动计算调用函数的脚本
import pefile
def custom_hash(name):
"""根据反汇编还原的自定义哈希算法计算函数名的哈希值"""
v32 = -1
for c in name:
v32 += ord(c) + 32 * v32
return v32 & 0xFFFFFFFF # 限定为32位无符号整数
def find_matching_export(dll_path, target_hash):
pe = pefile.PE(dll_path)
if not hasattr(pe, 'DIRECTORY_ENTRY_EXPORT'):
print("该 DLL 没有导出函数")
return
matches = []
for exp in pe.DIRECTORY_ENTRY_EXPORT.symbols:
if not exp.name:
continue
func_name = exp.name.decode('utf-8')
h = custom_hash(func_name)
if h == target_hash:
matches.append(func_name)
if matches:
print(f"找到匹配的函数名 (哈希值 0x{target_hash:08X}):")
for name in matches:
print(" ->", name)
else:
print(f"未找到匹配的函数名 (哈希值 0x{target_hash:08X})")
if __name__ == "__main__":
dll_path1 = "user32.dll" # 或者你上传的路径
dll_path2 = "KernelBase.dll" # 或者你上传的路径
dll_path3 ="ntdll.dll"
choose =0x12345678
target_hash = 0x84157815
if choose == 0x12345678:
dll_path = dll_path1
elif choose == 0x1234567A:
dll_path = dll_path2
elif choose == 0x12345679:
dll_path = dll_path3
find_matching_export(dll_path, target_hash)
继续跟进sub_7FF6CE9C1320
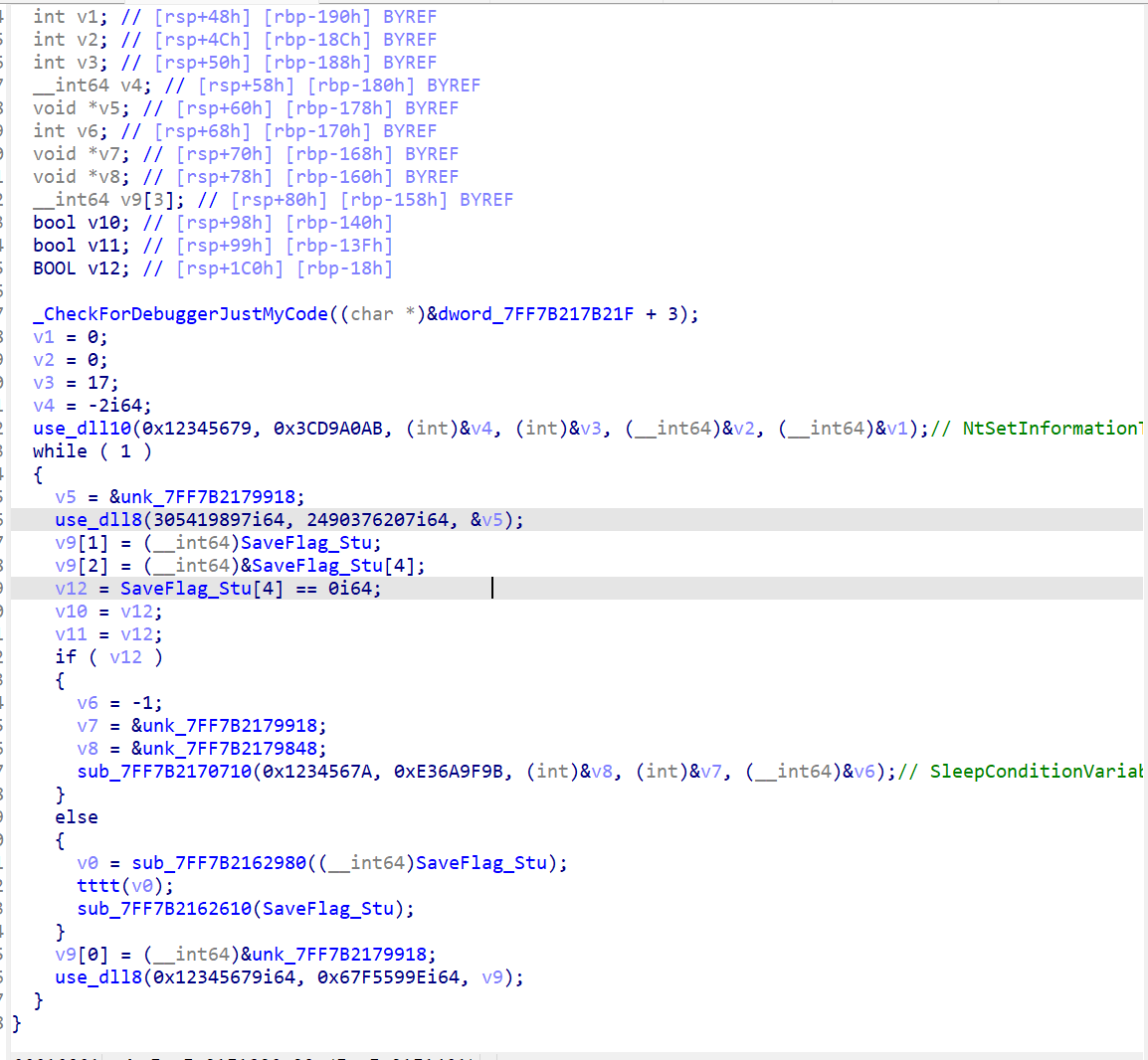
再进tttt(自己命名的),找到了核心分发逻辑

在switch处下断点,动调到这儿,f8跟进,发现先进了encode1,继续走,这里使用了ScyllaHide越过反调试,使用AI插件(ds)把函数名改了改
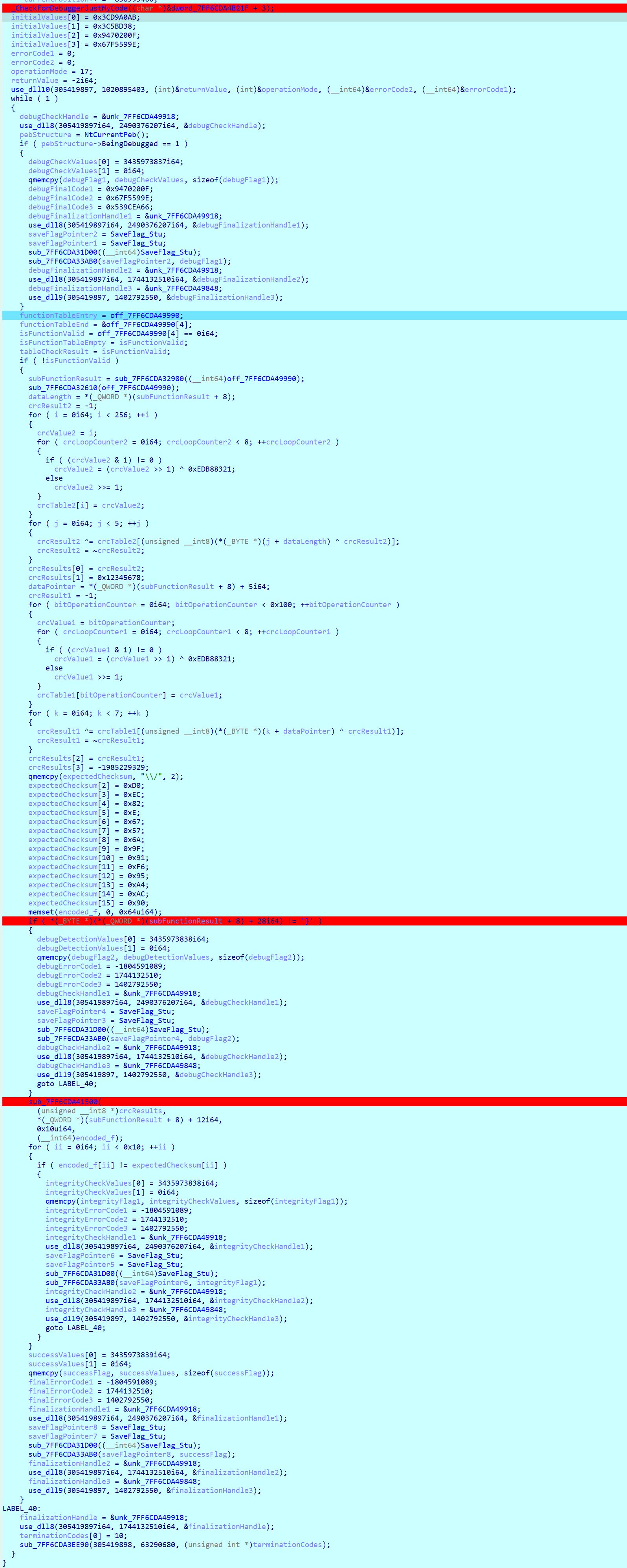
发现这里有一段加密,但是跟着动调发现没有进去,接着走,发现退到分发处,然后又进encode1,以此往复好多次,看输出应该是在加载各种dll
最后弹出窗口,随便输一串进去,然后跟着走
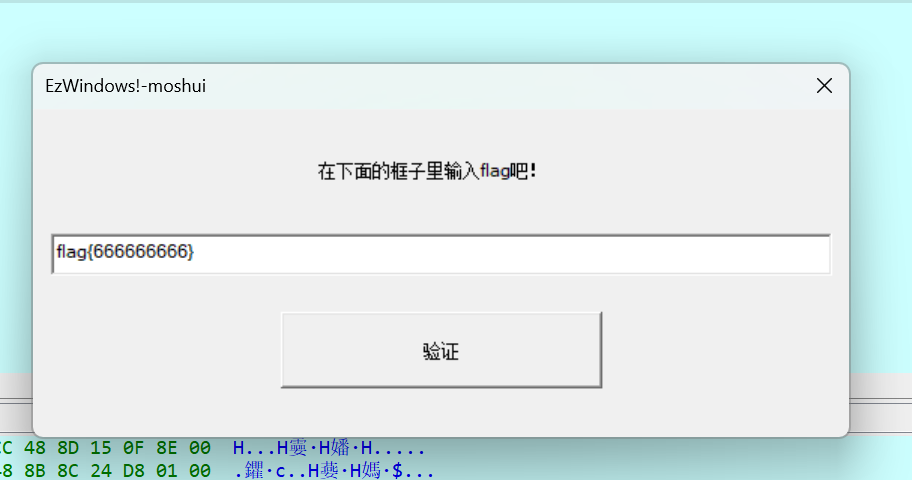
发现先进case4,就是验证flag的前五位是否为flag{,这里的GetDlgItemTextA也挺关键的,确定输入的flag被存在了v5数组
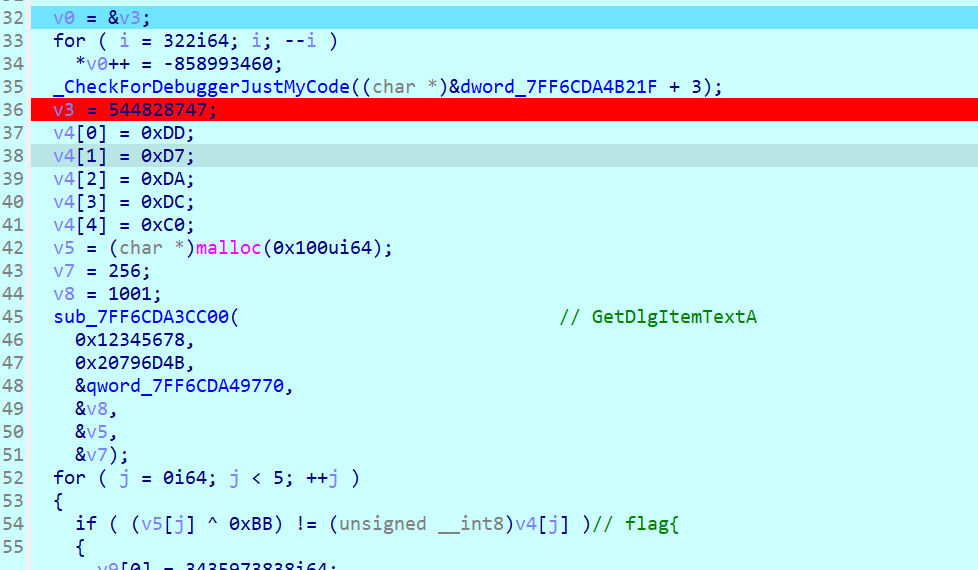
如下:
#include<stdio.h>
int main(){
unsigned char v4[5]={};
v4[0] = 0xDD;
v4[1] = 0xD7;
v4[2] = 0xDA;
v4[3] = 0xDC;
v4[4] = 0xC0;
for(int i=0;i<5;i++){
printf("%c",v4[i]^0xBB);
}
//flag{
return 0;
}继续走,程序进encode2
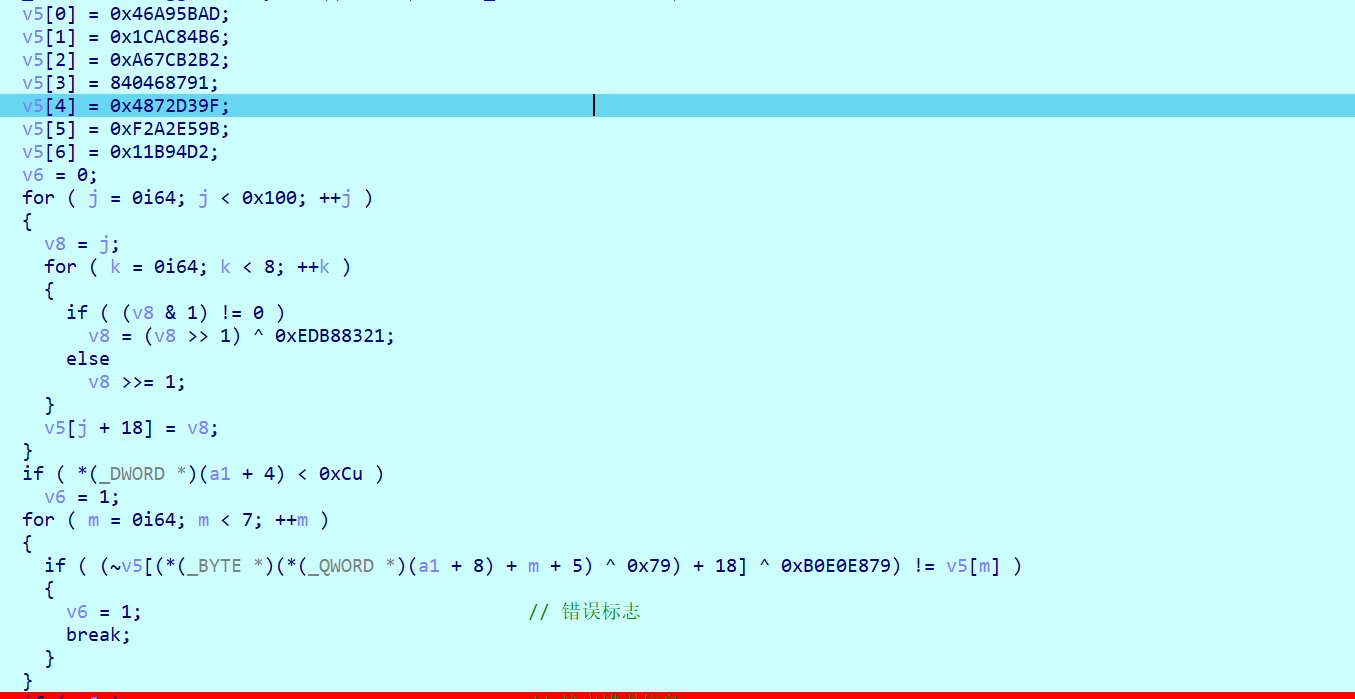
又是一个验证,使用CRC算法+异或加密后与v5比较,注意这里的m是index,m+5那就是从第六个字符开始验证,循环7次说明依次验证共7个字符
先异或0x79再做index取v5[index]再取反,最后和前面初始化的v5[0~6]做判断。
其中v5[index]是由前面CRC算法构建crc_table得到的。
# 1. 生成CRC表
crc_table = [0] * 256
for i in range(256):
crc = i&0xffffffff
for _ in range(8):
if crc & 1:
crc = ((crc >> 1) ^ 0xEDB88321)&0xffffffff
else:
crc >>= 1
crc_table[i] = crc
# 2. 逆向计算每个位置的字节
fixed_values = [0x46A95BAD, 0x1CAC84B6, 0xA67CB2B2, 0x32188937,
0x4872D39F, 0xF2A2E59B, 0x11B94D2]
for m in range(7):
found = None
for b in range(28,132):
if ((~crc_table[(b ^ 0x79)&0xff]^0xB0E0E879)&0xffffffff) == fixed_values[m]:
print(chr(b), end="")
break
#moshui_
# 3. 构建合法输入
# 假设a1+8指向的数据缓冲区至少12字节
# 其中偏移5-11字节必须等于solution中的值
# 其他字节可以是任意值(可能有其他约束)得到7个字符moshui_
可以直接进encode1看
第一个CRC,和前面一样的,结果存给crcResults数组
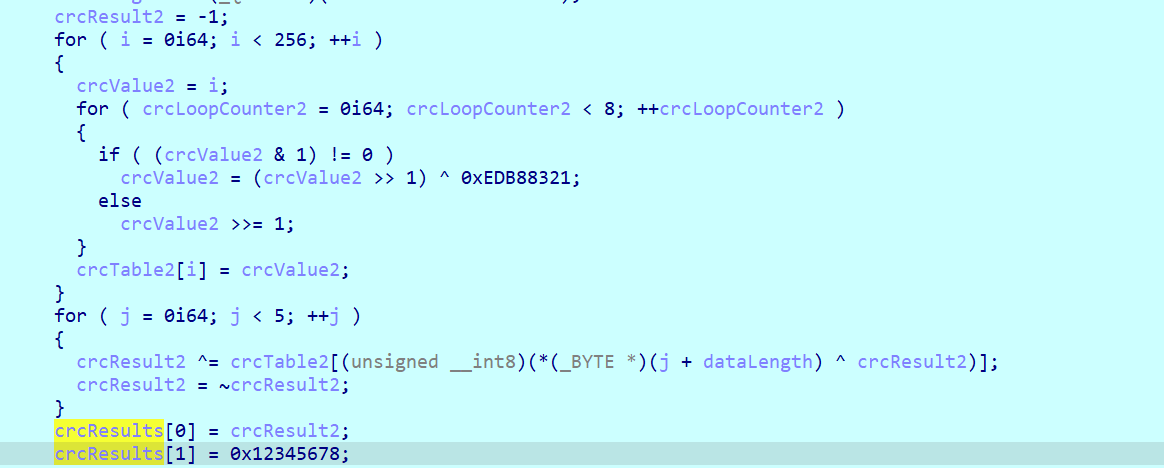
第二个CRC,存给[2]和[3]
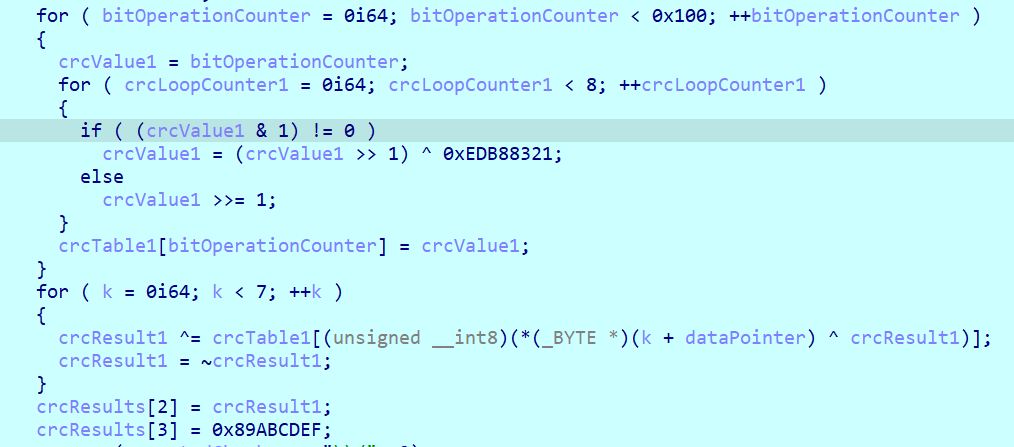
验证数据,以及做了一个判断flag第29位是否为'}'
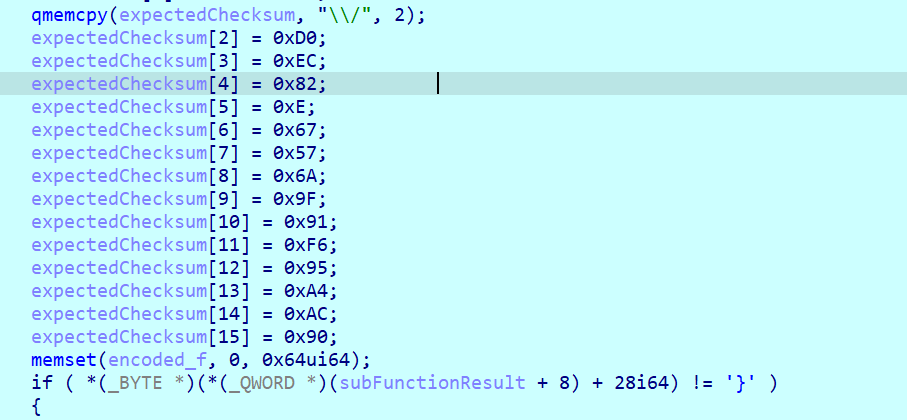
接下来是一个加密和最后的验证
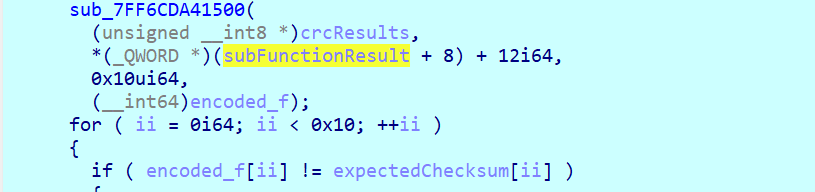
进sub_7FF6CDA41500,看密钥扩展和加密函数(名字是后来命名的),确定是IDEA算法,密钥就是前面的crcResults数组
用的别人的exp,如下:
#include <iostream>
#include <bitset>
#include <cmath>
#include <windows.h>
#include <algorithm>
using namespace std;
typedef bitset<16> code;
typedef bitset<128> key;
bitset<16> sub_key[52];
bitset<16> inv_sub_key[52];
code XOR(code code_1, code code_2)
{
return code_1 ^ code_2;
}
code Plus(code code_1, code code_2)
{
int tmp = 0;
for (int i = 0; i < 16; i++)
{
tmp += code_1[i] * pow(2, i) + code_2[i] * pow(2, i);
}
tmp %= 65536;
return bitset<16>(tmp);
}
code invPlus(code code_in)
{
int tmp = 0;
for (int i = 0; i < 16; i++)
tmp += code_in[i] * pow(2, i);
tmp = 65536 - tmp;
return bitset<16>(tmp);
}
code Times(code code_1, code code_2)
{
long long tmp_1 = 0, tmp_2 = 0;
for (int i = 0; i < 16; i++)
{
tmp_1 += code_1[i] * pow(2, i);
tmp_2 += code_2[i] * pow(2, i);
}
if (tmp_1 == 0)
tmp_1 = 65536;
if (tmp_2 == 0)
tmp_2 = 65536;
long long tmp = (tmp_1 * tmp_2) % 65537;
return bitset<16>(tmp == 65536 ? 0 : tmp);
}
void Exgcd(int a, int b, int &x, int &y)
{
if (!b)
x = 1, y = 0;
else
Exgcd(b, a % b, y, x), y -= a / b * x;
}
code invTimes(code code_in)
{
int tmp = 0;
for (int i = 0; i < 16; i++)
tmp += code_in[i] * pow(2, i);
int x, y;
int p = 65537;
Exgcd(tmp, p, x, y);
x = (x % p + p) % p;
return bitset<16>(x);
}
void subkeys_get(code keys_input[8])
{
key keys;
for (int i = 0; i < 8; i++)
for (int j = 0; j < 16; j++)
keys[j + 16 * i] = keys_input[7 - i][j];
for (int i = 0; i < 8; i++)
for (int j = 0; j < 16; j++)
sub_key[i][15 - j] = keys[127 - (j + 16 * i)];
for (int i = 0; i < 5; i++)
{
key tmp_keys = keys >> 103;
keys = (keys << 25) | tmp_keys;
for (int j = (8 + 8 * i); j < (8 * (i + 2)); j++)
for (int k = 0; k < 16; k++)
sub_key[j][15 - k] = keys[127 - (k + 16 * (j - 8 - 8 * i))];
}
key tmp_keys = keys >> 103;
keys = (keys << 25) | tmp_keys;
for (int i = 48; i < 52; i++)
for (int j = 0; j < 16; j++)
sub_key[i][15 - j] = keys[127 - (j + 16 * (i - 48))];
}
void inv_subkeys_get(code sub_key[52])
{
for (int i = 6; i < 48; i += 6)
{
inv_sub_key[i] = invTimes(sub_key[48 - i]);
inv_sub_key[i + 1] = invPlus(sub_key[50 - i]);
inv_sub_key[i + 2] = invPlus(sub_key[49 - i]);
inv_sub_key[i + 3] = invTimes(sub_key[51 - i]);
}
for (int i = 0; i < 48; i += 6)
{
inv_sub_key[i + 4] = sub_key[46 - i];
inv_sub_key[i + 5] = sub_key[47 - i];
}
inv_sub_key[0] = invTimes(sub_key[48]);
inv_sub_key[1] = invPlus(sub_key[49]);
inv_sub_key[2] = invPlus(sub_key[50]);
inv_sub_key[3] = invTimes(sub_key[51]);
inv_sub_key[48] = invTimes(sub_key[0]);
inv_sub_key[49] = invPlus(sub_key[1]);
inv_sub_key[50] = invPlus(sub_key[2]);
inv_sub_key[51] = invTimes(sub_key[3]);
}
bitset<64> dencrypt(bitset<64> cipher)
{
bitset<16> I_1, I_2, I_3, I_4;
for (int i = 0; i < 16; i++)
{
I_1[15 - i] = cipher[63 - i];
I_2[15 - i] = cipher[47 - i];
I_3[15 - i] = cipher[31 - i];
I_4[i] = cipher[i];
}
for (int i = 0; i < 48; i += 6)
{
bitset<16> tmp_1 = Times(inv_sub_key[i], I_1);
bitset<16> tmp_2 = Plus(inv_sub_key[i + 1], I_2);
bitset<16> tmp_3 = Plus(inv_sub_key[i + 2], I_3);
bitset<16> tmp_4 = Times(inv_sub_key[i + 3], I_4);
bitset<16> tmp_5 = XOR(tmp_1, tmp_3);
bitset<16> tmp_6 = XOR(tmp_2, tmp_4);
bitset<16> tmp_7 = Times(inv_sub_key[i + 4], tmp_5);
bitset<16> tmp_8 = Plus(tmp_6, tmp_7);
bitset<16> tmp_9 = Times(tmp_8, inv_sub_key[i + 5]);
bitset<16> tmp_10 = Plus(tmp_7, tmp_9);
I_1 = XOR(tmp_1, tmp_9);
I_2 = XOR(tmp_3, tmp_9);
I_3 = XOR(tmp_2, tmp_10);
I_4 = XOR(tmp_4, tmp_10);
}
bitset<16> Y_1 = Times(I_1, inv_sub_key[48]);
bitset<16> Y_2 = Plus(I_3, inv_sub_key[49]);
bitset<16> Y_3 = Plus(I_2, inv_sub_key[50]);
bitset<16> Y_4 = Times(I_4, inv_sub_key[51]);
bitset<64> plaint;
for (int i = 0; i < 16; i++)
{
plaint[i] = Y_4[i];
plaint[i + 16] = Y_3[i];
plaint[i + 32] = Y_2[i];
plaint[i + 48] = Y_1[i];
}
return plaint;
}
int main()
{
// 后16字节进行IDEA解密
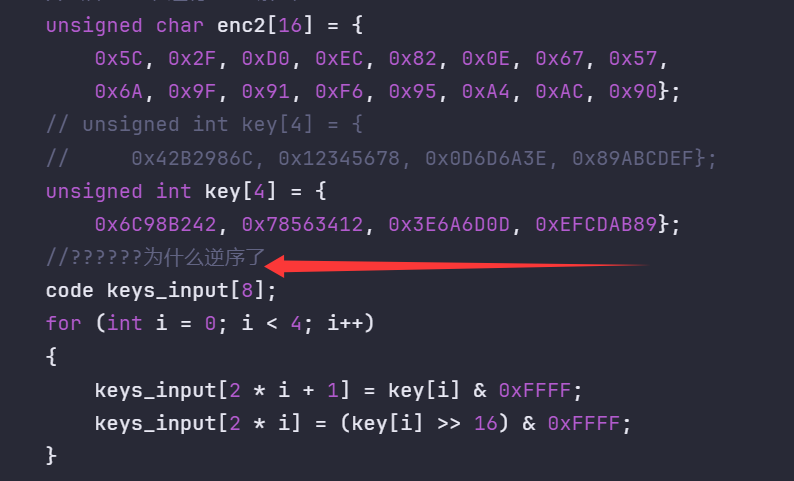
unsigned char enc2[16] = {
0x5C, 0x2F, 0xD0, 0xEC, 0x82, 0x0E, 0x67, 0x57,
0x6A, 0x9F, 0x91, 0xF6, 0x95, 0xA4, 0xAC, 0x90};
// unsigned int key[4] = {
// 0x42B2986C, 0x12345678, 0x0D6D6A3E, 0x89ABCDEF};
unsigned int key[4] = {
0x6C98B242, 0x78563412, 0x3E6A6D0D, 0xEFCDAB89};
//??????为什么逆序了
code keys_input[8];
for (int i = 0; i < 4; i++)
{
keys_input[2 * i + 1] = key[i] & 0xFFFF;
keys_input[2 * i] = (key[i] >> 16) & 0xFFFF;
}
unsigned char result[16];
bitset<64> cipher1, cipher2;
for (int i = 0; i < 8; i++)
{
for (int j = 0; j < 8; j++)
{
cipher1[63 - (i * 8 + j)] = (enc2[i] >> (7 - j)) & 1;
cipher2[63 - (i * 8 + j)] = (enc2[i + 8] >> (7 - j)) & 1;
}
}
subkeys_get(keys_input);
inv_subkeys_get(sub_key);
bitset<64> plain1 = dencrypt(cipher1);
bitset<64> plain2 = dencrypt(cipher2);
uint64_t plain1_val = plain1.to_ullong();
uint64_t plain2_val = plain2.to_ullong();
uint8_t dec2[16]{};
memcpy(dec2, &plain2_val, 8);
memcpy(dec2 + 8, &plain1_val, 8);
reverse(dec2, dec2 + 16);
printf("%.16s\n", dec2);
return 0;
}
//build_this_block一个疑惑,有没有大佬解答一下
最后把flag拼起来就是
flag{moshui_build_this_block}总结
很好的题使我旋转,ScyllaHide插件真强,复现还用到了AI插件,辅助命名也挺不错的。对TLS回调的理解进一步加深,以及闻所未闻的IDEA算法
至于官方WP里说的多线程啥的还是不太懂,是每次都能回到分发处吗?有没有大佬教教

EzObf
整体逻辑
去混淆
固定随机数种子,随机生成XXTEA算法的密钥
XXTEA算法加密,轮数固定为7
复现
看main发现插入了很多无用指令,先push一堆寄存器的值再pop,这对程序没有任何影响(混淆),后面也是这样,只有红圈处才是真实的指令(popfq与pushfq之间), ** ⽽底下的jmp rax则是跳到下⼀个块 , 也就是说,这个混淆只是把指令打散了**,我们把他抠出来就行了
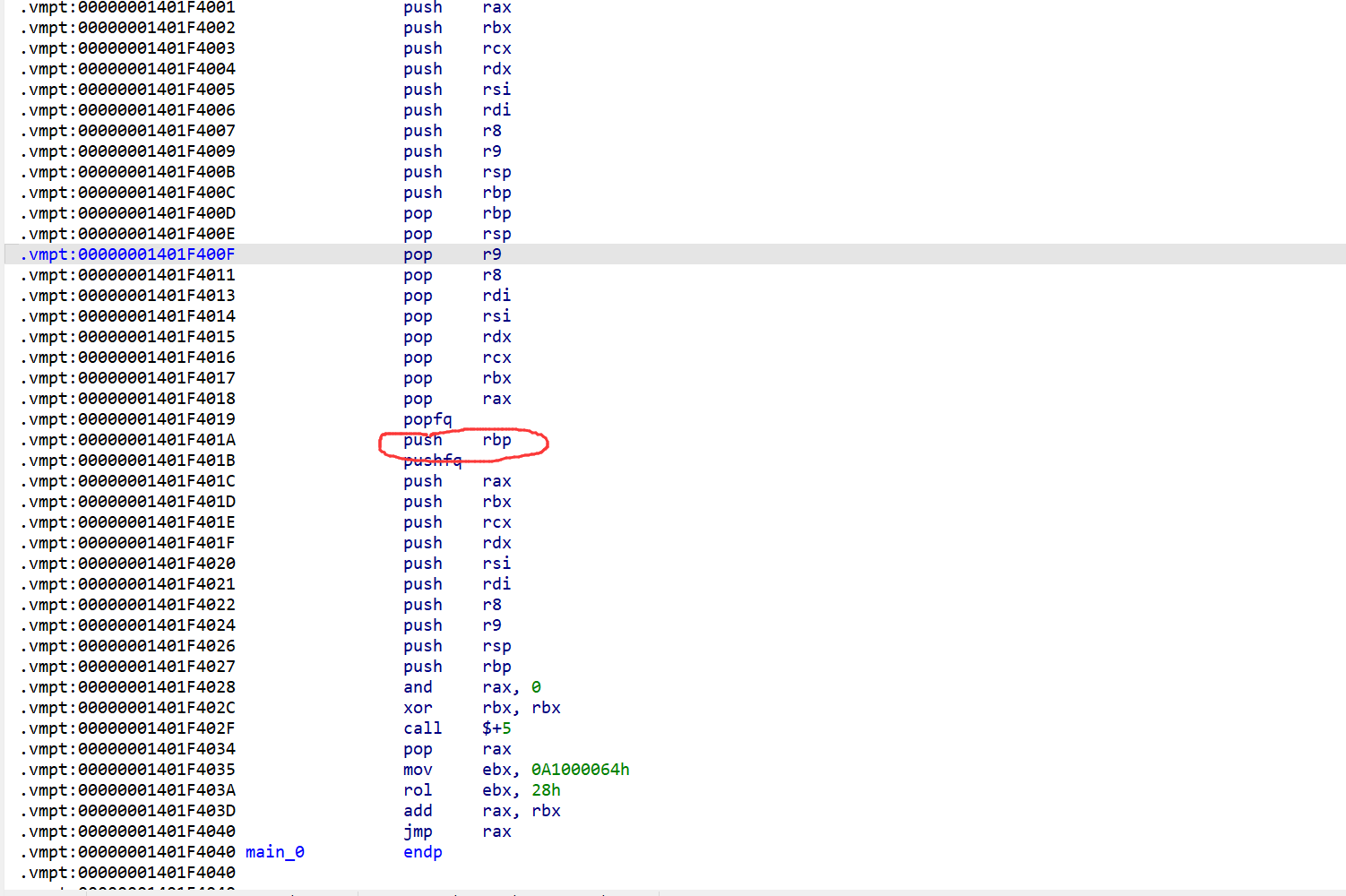
第一步跟着官方WP走,用脚本nop
static NopCode(Addr, Length)
{
auto i;
for (i = 0; i < Length; i++)
{
PatchByte(Addr + i, 0x90);
}
}
static rol(value, count, bits = 32)
{
count = count % bits;
return ((value << count) | (value >> (bits - count))) & ((1 << bits) - 1);
}
// 搜索真实汇编代码的下一个地址
static FindEnd(Addr)
{
auto i;
for (i = 0; i < 0x90; i++)
{
auto v = Dword(Addr + i);
if (v == 0x5153509C)
{
return Addr + i;
}
}
return 0;
}
// 搜索最后的jmp rax指令
static FindJmpRax(Addr)
{
auto i;
for (i = 0; i < 0x90; i++)
{
auto v = Word(Addr + i);
if (v == 0xE0FF)
{
return Addr + i;
}
}
return 0;
}
// 搜索call $+5
static FindCall(Addr)
{
auto i;
for (i = 0; i < 0x90; i++)
{
auto v = Dword(Addr + i);
if (v == 0xE8)
{
return Addr + i;
}
}
return 0;
}
static main()
{
auto StartAddr = 0x1401F400D;
while (1)
{
// 搜索真实汇编代码的下一个指令地址
auto EndAddr = FindEnd(StartAddr);
if (EndAddr == 0)
{
break;
}
// 真实汇编代码的字节长度
auto CodeLength = EndAddr - addr - 13;
// 搜索Call $+5
auto CallAddr = FindCall(addr + 13 + CodeLength);
if (CallAddr == 0)
{
break;
}
// call $+5的下一条指令地址,即call时push到栈的返回地址
auto CalcAddr = CallAddr + 5;
auto ebx = Dword(CalcAddr + 2);
auto rol_Value = Byte(CalcAddr + 8);
auto Mode = Dword(CalcAddr + 9);
ebx = rol(ebx, rol_Value);
// 搜索最尾部的jmp rax指令地址
auto JmpRaxAddr = FindJmpRax(addr);
if (JmpRaxAddr == 0)
{
break;
}
// 第一部分垃圾指令长度
auto TrushCodeLength_1 = CallAddr - (addr + 13 + CodeLength);
// 第二部分垃圾指令长度
auto TrushCodeLength_2 = JmpRaxAddr - CallAddr + 2;
// Nop掉无用的所有代码
NopCode(CallAddr, TrushCodeLength_2);
NopCode(addr, 13);
NopCode(addr + 13 + CodeLength, TrushCodeLength_1);
// 一共两种地址计算,加和减
if (Mode == 0xffC32B48)
{
CalcAddr = CalcAddr - ebx;
}
if (Mode == 0xffC30348)
{
CalcAddr = CalcAddr + ebx;
}
auto JmpCodeAddr = EndAddr;
// 计算相对跳转地址
auto JmpOffset = CalcAddr - JmpCodeAddr + 5;
// 写入jmp指令
PatchByte(JmpCodeAddr, 0xE9);
PatchDword(JmpCodeAddr + 1, JmpOffset);
// jmp的地址为下一次deobf起始地址
addr = CalcAddr;
}
}
发现运行在IDC中报好多错,找AI换成IDApython脚本,版本为8.3(我的ida版本)
from ida_bytes import patch_byte, patch_dword
from ida_bytes import get_byte, get_word, get_dword
from ida_kernwin import msg
def nop_code(addr, length):
for i in range(length):
patch_byte(addr + i, 0x90)
def rol(value, count, bits=32):
count = count % bits
return ((value << count) | (value >> (bits - count))) & ((1 << bits) - 1)
# 搜索真实汇编代码的下一个地址
def find_end(addr):
for i in range(0x90):
v = get_dword(addr + i)
if v == 0x5153509C:
return addr + i
return 0
# 搜索最后的jmp rax指令
def find_jmp_rax(addr):
for i in range(0x90):
v = get_word(addr + i)
if v == 0xE0FF: # opcode for JMP RAX: FF E0
return addr + i
return 0
# 搜索call $+5
def find_call(addr):
for i in range(0x90):
# 这里只检查一个字节更合适,因为call +5 是 E8 00 00 00 00
v = get_byte(addr + i)
if v == 0xE8:
return addr + i
return 0
def main():
addr = 0x1401F400D
while True:
# 搜索真实汇编代码的下一个指令地址
end_addr = find_end(addr)
if end_addr == 0:
break
# 真实汇编代码的字节长度
code_length = end_addr - addr - 13
# 搜索Call $+5
call_addr = find_call(addr + 13 + code_length)
if call_addr == 0:
break
# call $+5 的下一条指令地址
calc_addr = call_addr + 5
ebx = get_dword(calc_addr + 2)
rol_value = get_byte(calc_addr + 8)
mode = get_dword(calc_addr + 9)
ebx = rol(ebx, rol_value)
# 搜索最后的jmp rax
jmp_rax_addr = find_jmp_rax(addr)
if jmp_rax_addr == 0:
break
# 第一部分垃圾指令长度
trush_len1 = call_addr - (addr + 13 + code_length)
# 第二部分垃圾指令长度
trush_len2 = jmp_rax_addr - call_addr + 2
# Nop 掉无用代码
nop_code(call_addr, trush_len2)
nop_code(addr, 13)
nop_code(addr + 13 + code_length, trush_len1)
# 计算真实代码地址
if mode == 0xffC32B48:
calc_addr = calc_addr - ebx
elif mode == 0xffC30348:
calc_addr = calc_addr + ebx
jmp_code_addr = end_addr
jmp_offset = calc_addr - jmp_code_addr - 5 # 相对地址从下一条指令算起
# 写入jmp跳转
patch_byte(jmp_code_addr, 0xE9)
patch_dword(jmp_code_addr + 1, jmp_offset)
# 下一轮
addr = calc_addr
# 执行主函数
if __name__ == '__main__':
main()
nop后清爽多了,执行完,把main_0剩余代码都手动nop即可。
然后跟着jmp走把一路上那些堆成块的数据打散,比如(注意先把main和一路上遇到的所有函数删了)

按D再esc回去
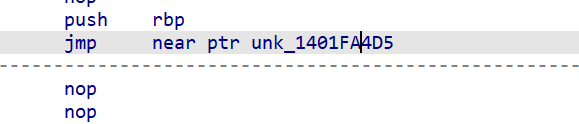
再jmp过来
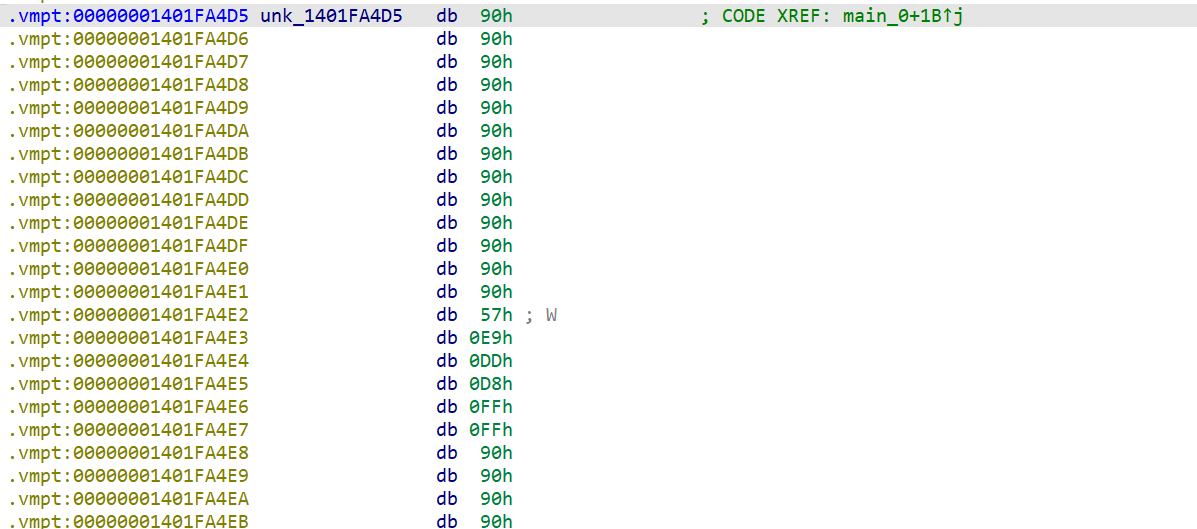
按C
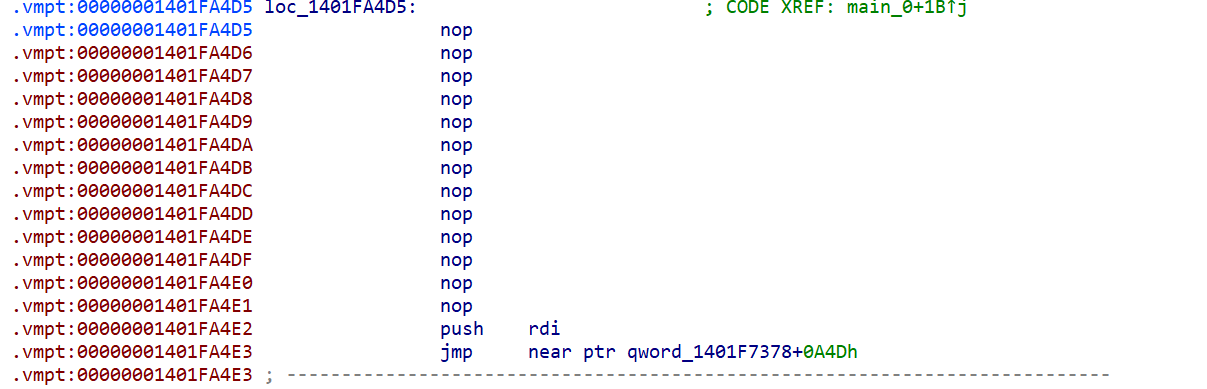
后面的以此类推,没多少,2分钟就整理好了
根据wp所说1401F7B81地址处为main的结束地址,找到那里,按E,把这里作为main的结束地址。PS:其实不需要这一步,按照以上步骤整理好后在main处按P即可正常f5(按了反而报错)
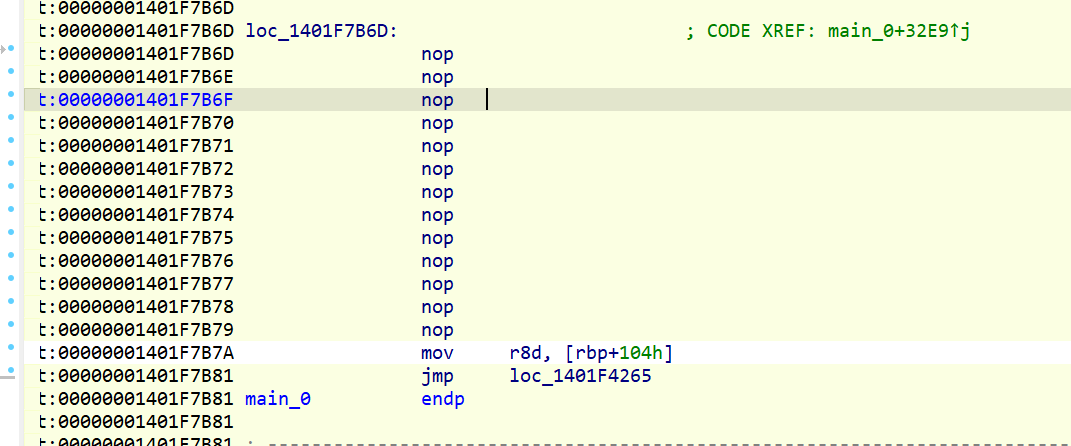
反编译出来如下:
// ----- Comment generated by Gepetto -----
//
// # 函数分析与重命名
//
// 这个函数看起来是一个反调试保护机制与某种加密/解密或验证逻辑的组合。让我分析它的主要功能:
//
// ## 功能分析
//
// 1.
// **反调试检查**:
// - 使用`IsDebuggerPresent()`检查是否在调试器中运行
// -
// 使用`CheckRemoteDebuggerPresent()`检查远程调试器
// - 使用`__rdtsc()`计时检查(检测单步调试)
//
// 2.
// **加密/解密逻辑**:
// - 初始化一些变量和数组
// - 使用伪随机数生成器(`srand`/`rand`)生成密钥
// -
// 执行某种加密/解密循环(可能是TEA或XTEA算法的变种)
// - 将结果与硬编码值(`v25`数组)进行比较
//
// 3. **行为**:
// -
// 如果检测到调试器或验证失败,可能会调用某些系统命令(`system`调用)
// - 看起来像是某种许可证验证或保护机制
//
// ## 更好的命名建议
// 根据功能,更好的名称可能是:
// - `VerifyLicenseAndAntiDebug`
// - `ProtectedCodeVerification`
// -
// `AntiDebugLicenseCheck`
// - `SecureCodeValidation`
// 如果知道更具体的上下文,可以给出更精确的名称。例如,如果这是游戏的一部分,可能是`GameAntiCheatVerification`。
//
// ## 代码特点
// 1. 使用了大量混淆技术(变量重命名、无意义操作)
// 2. 包含反逆向工程技术(调试器检测、时间检查)
// 3. 实现了某种加密算法(可能是TEA家族)
// 4.
// 最后与硬编码值比较进行验证
//
// 这个函数的主要目的是保护代码不被逆向工程分析,并在检测到调试或验证失败时采取某种行动(可能是退出或显示错误)。
//
// ----------------------------------------
//
int __fastcall main_0(int argc, const char **argv, const char **envp)
{
__int64 i; // rcx
int result; // eax
_DWORD *v5; // rdi
HANDLE CurrentProcess; // rax
__int64 v7; // [rsp-20h] [rbp-468h] BYREF
_DWORD v8[2]; // [rsp+0h] [rbp-448h] BYREF
_BYTE v9[64]; // [rsp+8h] [rbp-440h] BYREF
_BYTE *v10; // [rsp+48h] [rbp-400h]
unsigned int v11; // [rsp+64h] [rbp-3E4h]
unsigned int v12; // [rsp+84h] [rbp-3C4h]
unsigned int v13; // [rsp+A4h] [rbp-3A4h]
int v14; // [rsp+C4h] [rbp-384h]
unsigned int v15; // [rsp+E4h] [rbp-364h]
unsigned int k; // [rsp+104h] [rbp-344h]
unsigned int v17; // [rsp+124h] [rbp-324h]
int v18; // [rsp+144h] [rbp-304h]
int v19; // [rsp+164h] [rbp-2E4h]
_DWORD v20[11]; // [rsp+188h] [rbp-2C0h] BYREF
unsigned __int16 v21; // [rsp+1B4h] [rbp-294h]
BOOL v22; // [rsp+1D4h] [rbp-274h] BYREF
unsigned __int64 j; // [rsp+1F8h] [rbp-250h]
unsigned __int64 v24; // [rsp+218h] [rbp-230h]
int v25[16]; // [rsp+238h] [rbp-210h]
unsigned __int64 m; // [rsp+278h] [rbp-1D0h]
unsigned int v27; // [rsp+404h] [rbp-44h]
unsigned int v28; // [rsp+408h] [rbp-40h]
unsigned int v29; // [rsp+40Ch] [rbp-3Ch]
__int64 v30; // [rsp+410h] [rbp-38h]
unsigned int v31; // [rsp+418h] [rbp-30h]
unsigned __int64 v32; // [rsp+420h] [rbp-28h]
v5 = v8;
for ( i = 174i64; i; --i )
*v5++ = -858993460;
v32 = (unsigned __int64)v8 ^ 0x1401D9000i64;
j___CheckForDebuggerJustMyCode(0x1401ED101i64);
memset(v9, 0, 0x20ui64);
sub_140087C02(0x1401A1190i64);
if ( !IsDebuggerPresent() )
{
sub_1400868E3();
v10 = v9;
memset(v20, 0, 0x10ui64);
v21 = 8;
v27 = 8;
v18 = 12;
v13 = 0;
v14 = 0x61C88646;
v19 = 0x95664B48;
v17 = 7;
v22 = 0;
CurrentProcess = GetCurrentProcess();
CheckRemoteDebuggerPresent(CurrentProcess, &v22);
if ( !v22 )
{
j_srand(0xAABBu);
for ( j = 0i64; j < 4; ++j )
v20[j] = j_rand();
while ( 1 )
{
v27 = v17--;
v28 = v27 != 0;
if ( !v28 )
break;
v13 += v14;
v15 = (v13 >> 2) & 3;
for ( k = 0; k < v21; ++k )
{
v24 = __rdtsc();
v11 = *(_DWORD *)&v10[4 * ((k + 1) % v21)];
v27 = (4 * v11) ^ (*(_DWORD *)&v10[4 * ((k + v21 - 1) % v21)] >> 5);
v28 = k + v21 - 1;
v29 = ((16 * *(_DWORD *)&v10[4 * (v28 % v21)]) ^ (v11 >> 3)) + v27;
v30 = ((unsigned __int8)v15 ^ (unsigned __int8)k) & 3;
v31 = (((*(_DWORD *)&v10[4 * (v28 % v21)] ^ v20[v30]) + (v11 ^ v13)) ^ v29) + *(_DWORD *)&v10[4 * k];
*(_DWORD *)&v10[4 * k] = v31;
v12 = v31;
if ( __rdtsc() - v24 > 0x83C0 )
goto LABEL_21;
}
}
v25[0] = 0xA9934E2F;
v25[1] = 0x30B90FA;
v25[2] = 0xDCBF1D3;
v25[3] = 0x328B5BDE;
v25[4] = 0x44FAB4E;
v25[5] = 0x1DCF0051;
v25[6] = 0x85EBBE55;
v25[7] = 0x93AA773A;
for ( m = 0i64; m < 4; ++m )
{
if ( v25[m] != v8[m + 2] )
{
sub_140087C02(0x1401A11A8i64);
j_system(byte_1401A11A0);
goto LABEL_21;
}
}
sub_140087C02(0x1401A11C0i64);
j_system(byte_1401A11A0);
}
}
LABEL_21:
j__RTC_CheckStackVars(&v7, (_RTC_framedesc *)&unk_1401A1140);
j___security_check_cookie((unsigned __int64)v8 ^ v32);
return result;
}XXTEA算法,改了Delta,以及密钥是靠随机数生成的,以及加密轮数固定了为7轮
exp:
#include <stdio.h>
#include <stdint.h>
#include<stdlib.h>
#define DELTA 0x61C88646//魔改出
#define MX (((z>>5^y<<2) + (y>>3^z<<4)) ^ ((sum^y) + (key[(p&3)^e] ^ z)))
void btea(uint32_t *v, int n, uint32_t const key[4])
{
uint32_t y, z, sum;
unsigned p, rounds, e;
if (n > 1) /* Coding Part */
{
rounds = 6 + 52/n;
sum = 0;
z = v[n-1];
do
{
sum += DELTA;
e = (sum >> 2) & 3;
for (p=0; p<n-1; p++)
{
y = v[p+1];
z = v[p] += MX;
}
y = v[0];
z = v[n-1] += MX;
}
while (--rounds);
}
else if (n < -1) /* Decoding Part */
{
n = -n;
rounds = 7;//注意这里轮数按照题意为7
sum = rounds*DELTA;
y = v[0];
do
{
e = (sum >> 2) & 3;
for (p=n-1; p>0; p--)
{
z = v[p-1];
y = v[p] -= MX;
}
z = v[n-1];
y = v[0] -= MX;
sum -= DELTA;
}
while (--rounds);
}
}
int main()
{
uint32_t v[8]= {
0xA9934E2F, 0x030B90FA,
0x0DCBF1D3, 0x328B5BDE,
0x044FAB4E, 0x1DCF0051,
0x85EBBE55, 0x93AA773A};
uint32_t k[4]= {};
srand(0xAABB);
for (int j = 0; j < 4; ++j )
k[j] = rand();
int n= -8; //n的绝对值表示v的长度,取正表示加密,取负表示解密
// v为要加密的数据是两个32位无符号整数
// k为加密解密密钥,为4个32位无符号整数,即密钥长度为128位
btea(v, n, k);
printf("%.32s\n", v);
return 0;
}//flag{th15_15_51mpLe_obf_R19Ht?}Summer
动调、手撕汇编
函数式编程,惰性计算,没看明白,照着WP走一遍
补基础知识
惰性计算
惰性不是迟缓: Twisted和Haskell - 《Twisted与异步编程入门》 - 书栈网 · BookStack↗
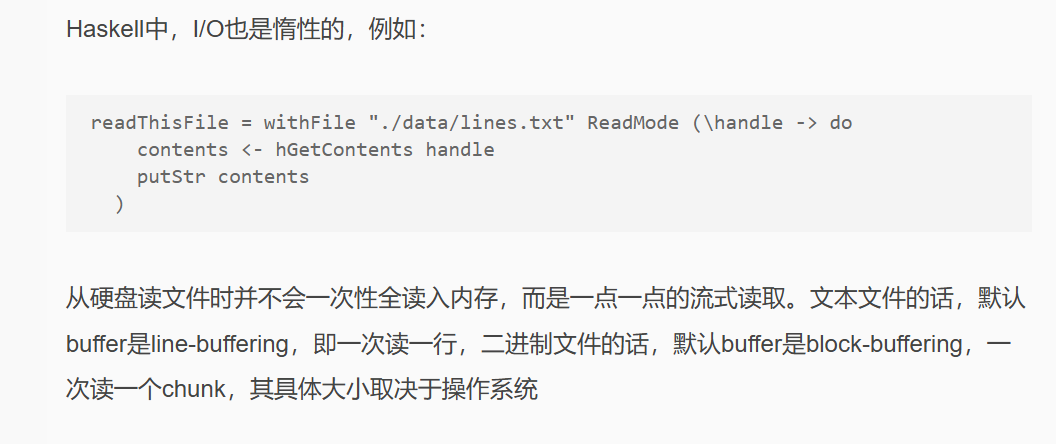
整体逻辑
- 获取用户输入字符串
- 加载用户输入字符串长度
- 加载密钥长度
- 加载密钥
- 密钥解密
- 解密后的密钥对用户输入的字符串进行RC4+异或加密
复现
跟着WP走一遍
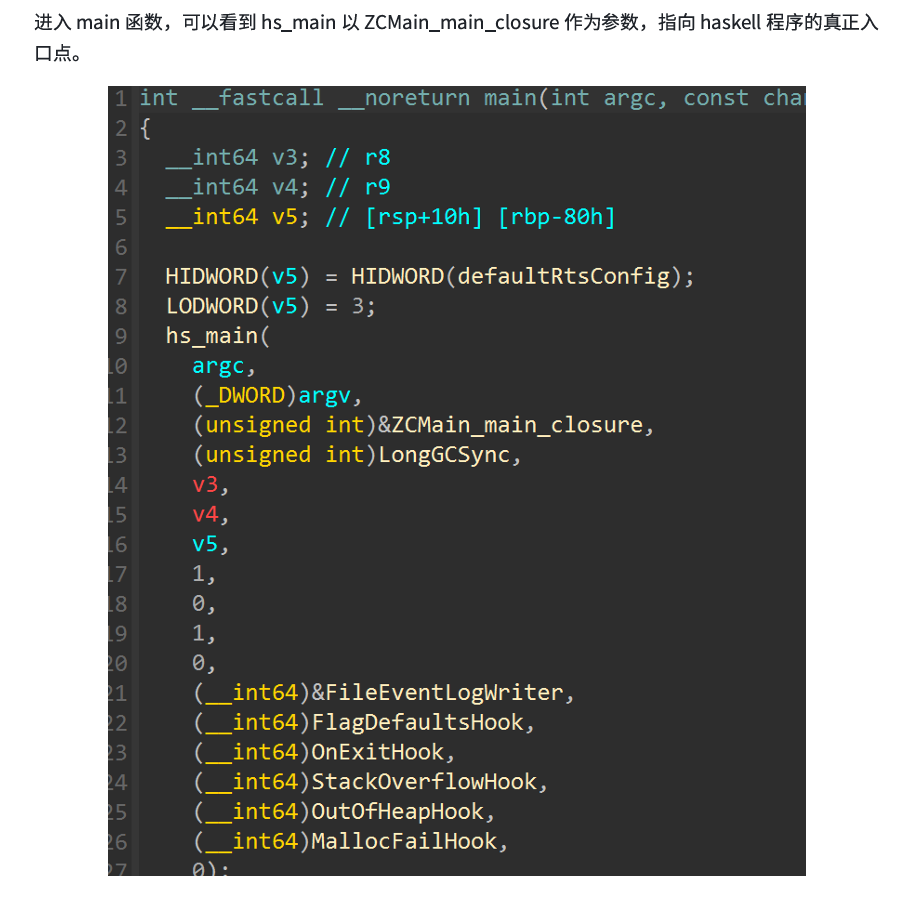
来到Main_main_info()
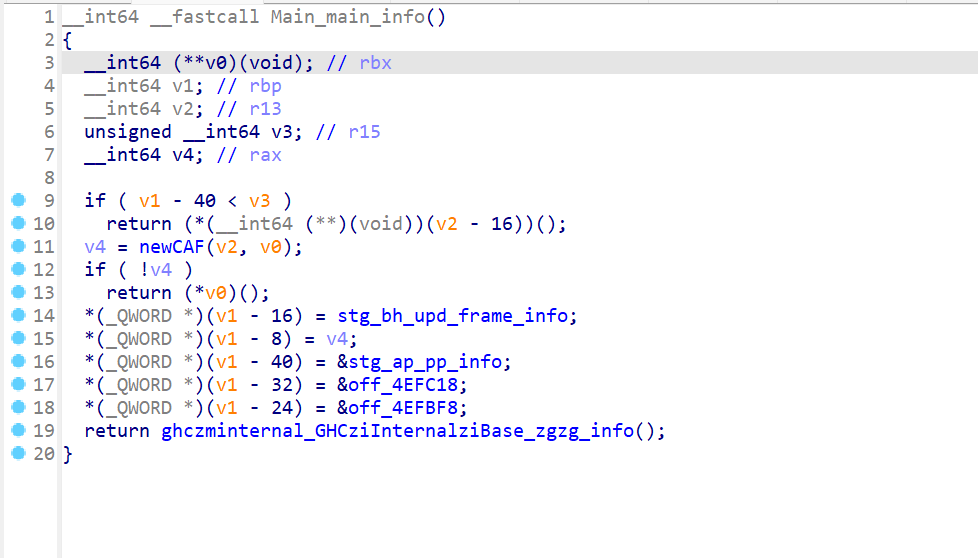
进off_4EFC18,跳到sub_40F318,进sub_40F2D0
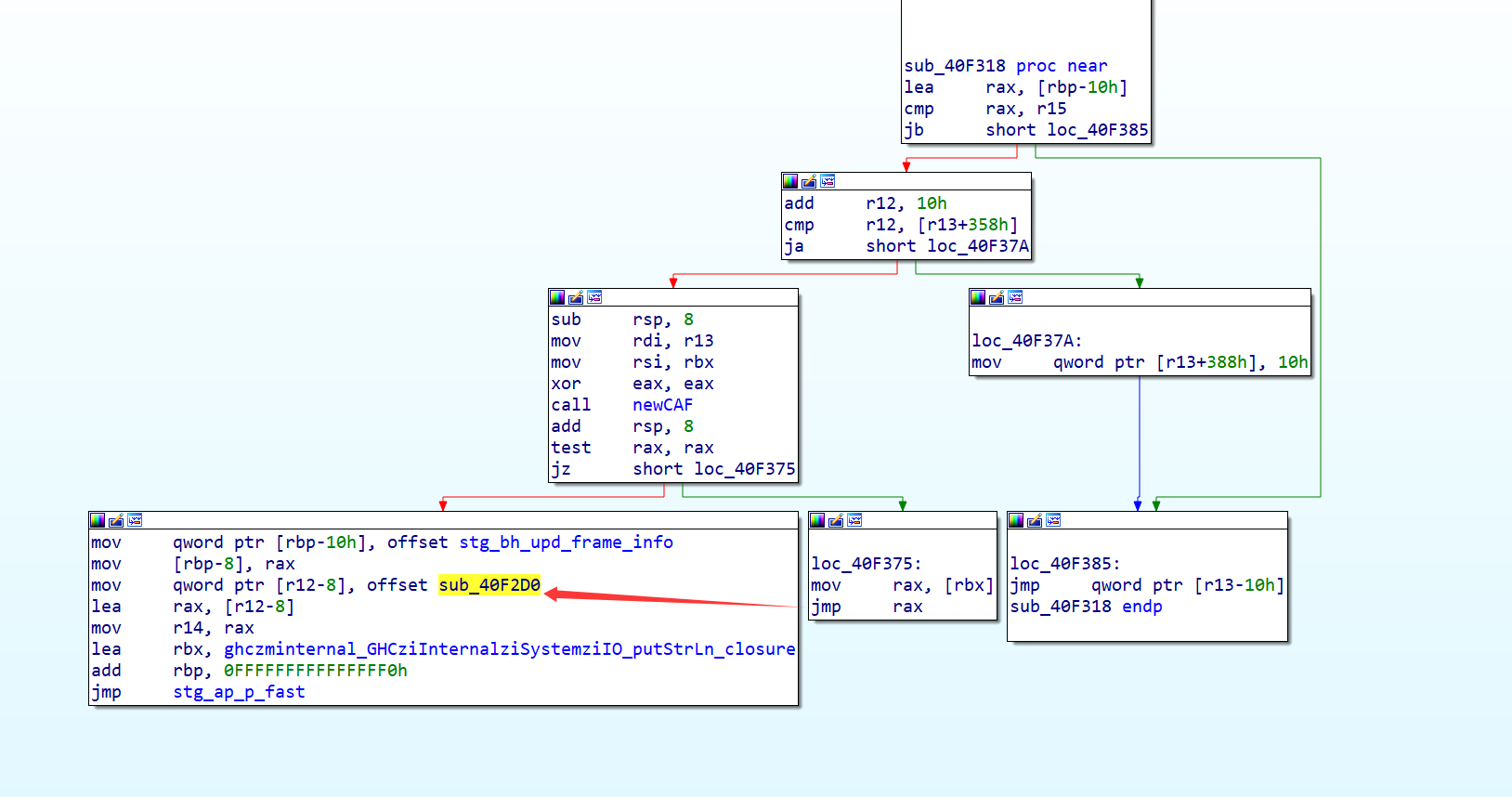
可以找到程序运行输出的第一段字符串,那这个函数就是在打印字符串
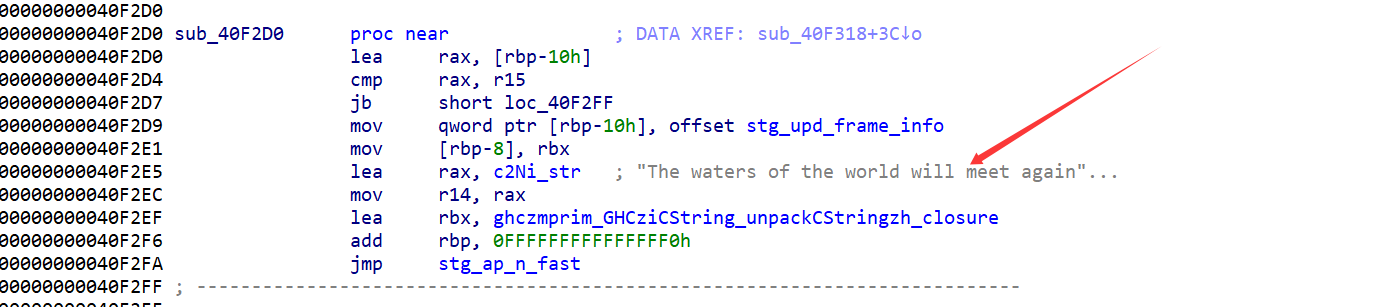
注意ghczminternal_GHCziInternalziList_length_info,这个函数是检测⻓度的,我们可以断在这⾥看密文和密钥的长度
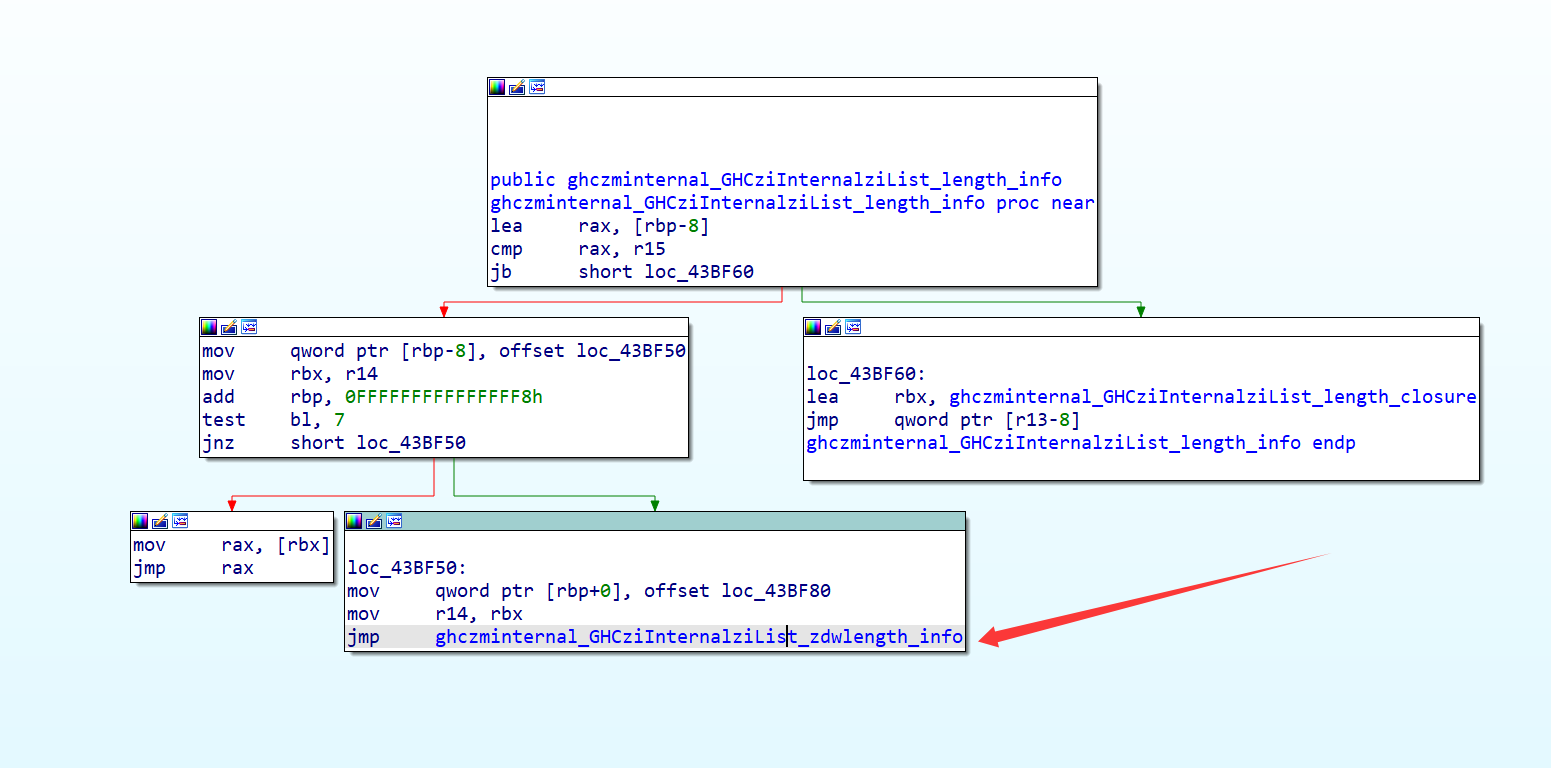
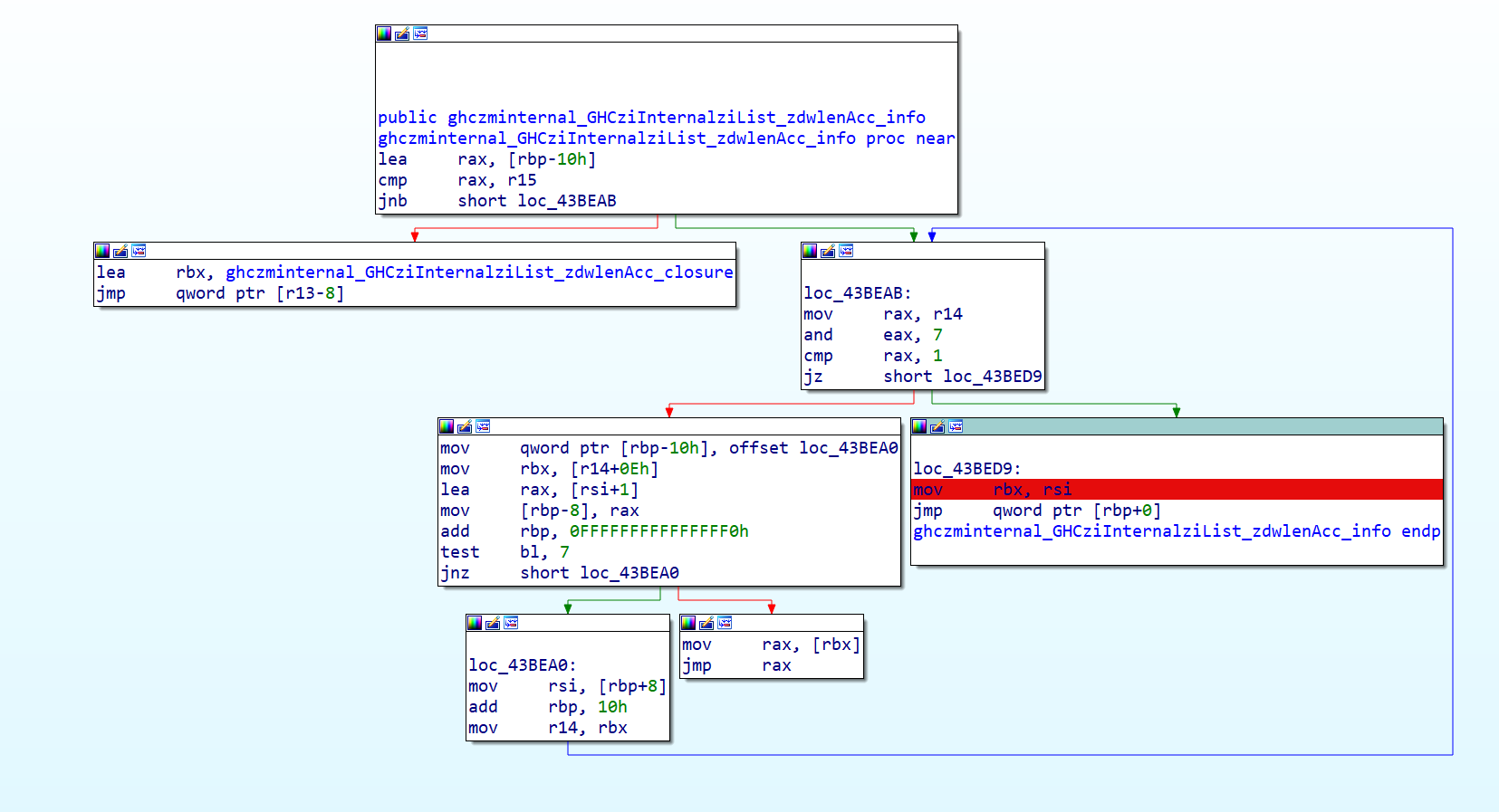
动调,输入1234567812345678后程序断在这里,可见先加载了长度

看WP说在43E370处有对字符的处理,好奇是怎么看出来的,手撕吗(
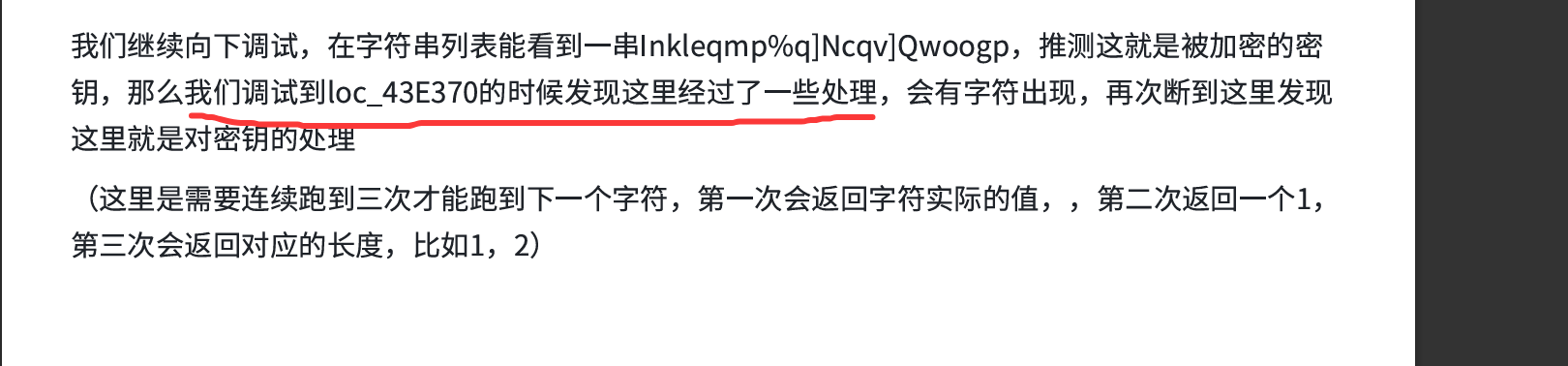
直接到43E370并在对应位置下断点

继续走发现回到的刚在断点那儿,rbx为0x16,正好就是加密字符串的长度


再走,来到了43E370处,rbx值为K、1,1,0、l,好像是每隔3次拿到key[i]加密后的值
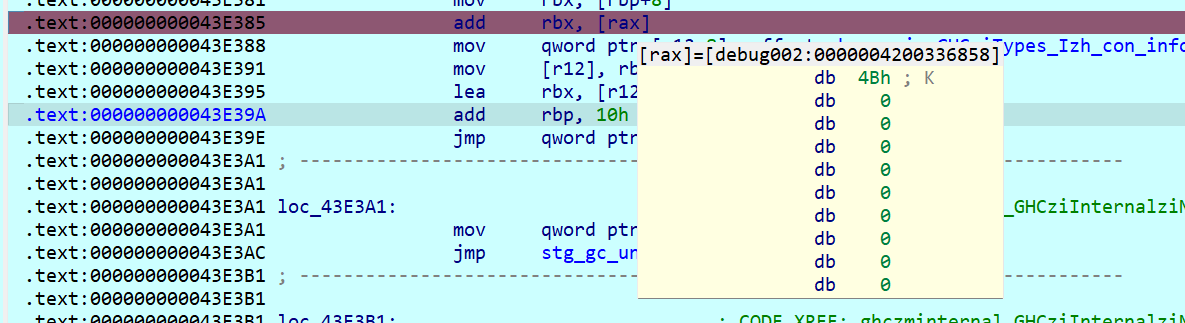
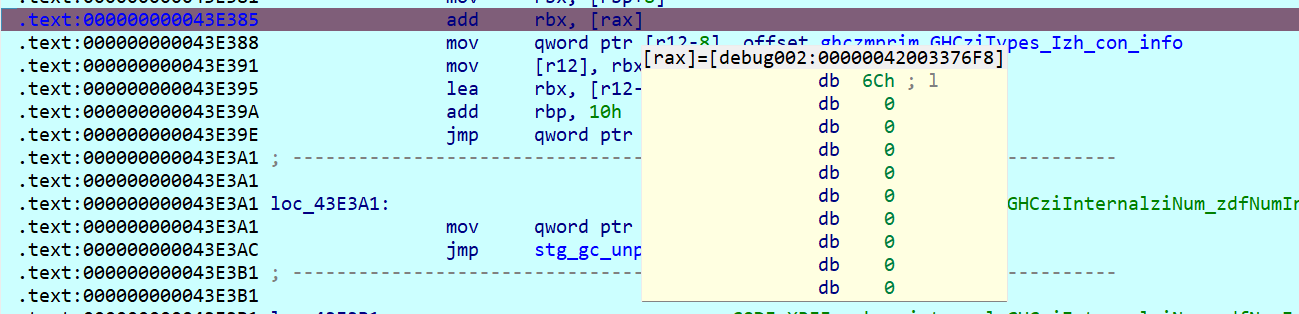
对比一下key[0]=‘I’以及key`[0]=‘K’,拿在线网站异或一下结果是0x2,尝试对key整体异或0x2
char key[]={"Inkleqmp%q]Ncqv]Qwoogp"};
for(int i=0;i<strlen(key);i++){
key[i]^=2;
}
printf("%s",key);
//Klingsor's_Last_Summer真正的密钥就是Klingsor’s_Last_Summer(克林索尔的最后夏天)
剩下完全靠WP里的了,一脸懵
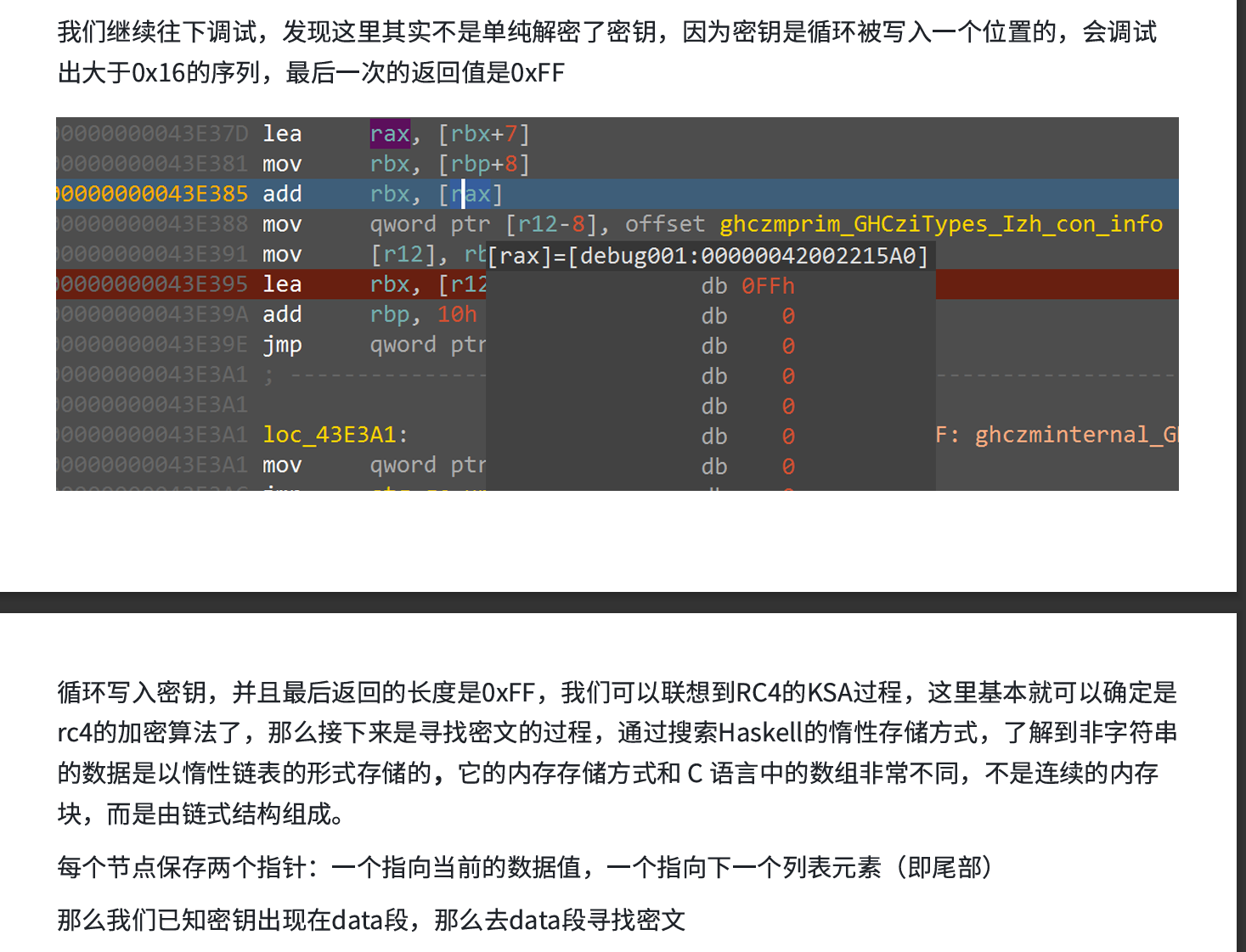
最重要的是这个惰性存储方式,它是离散的,不像正常定义一个数组一样开辟的一组连续的空间
在.data段里找这一段内容,发现了指针加元素的存储方式:
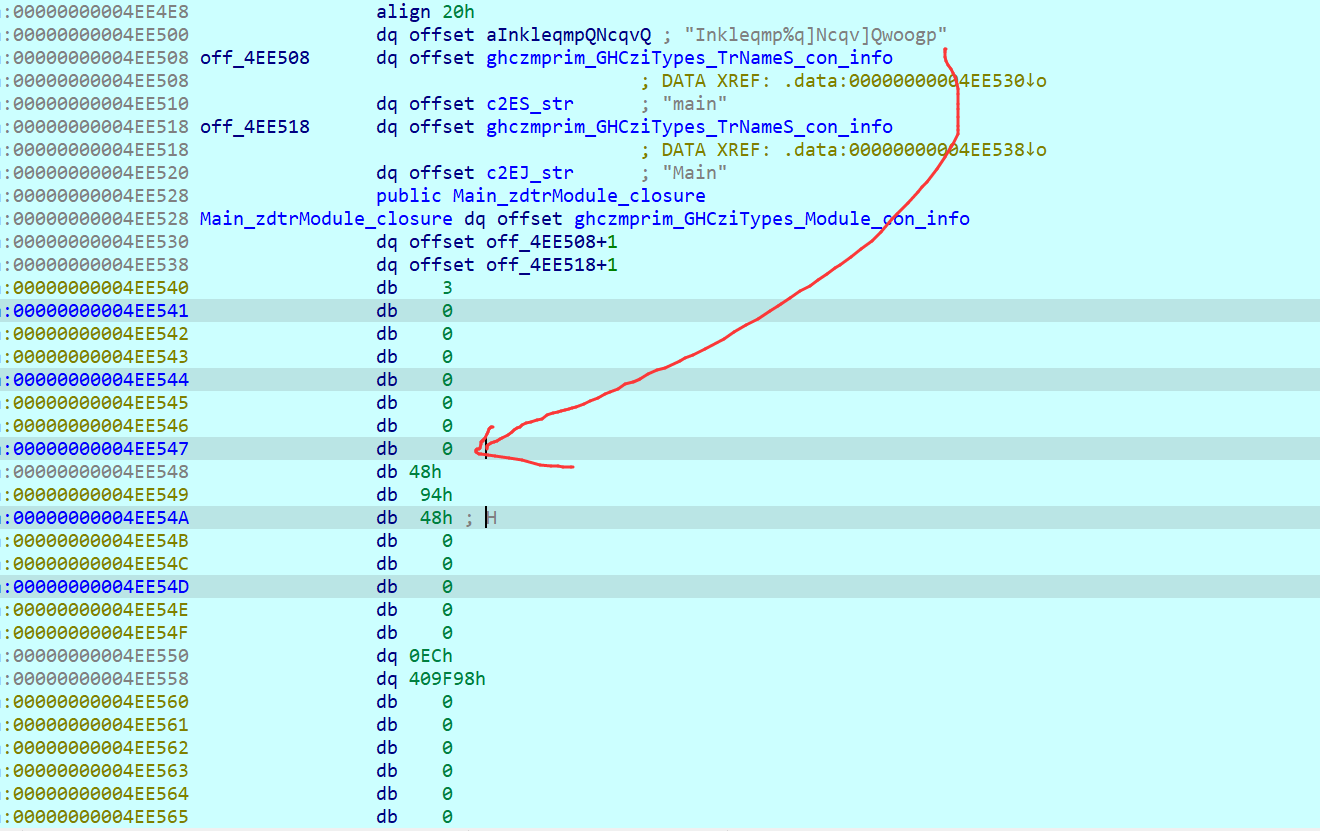
按d整理一下,对味了
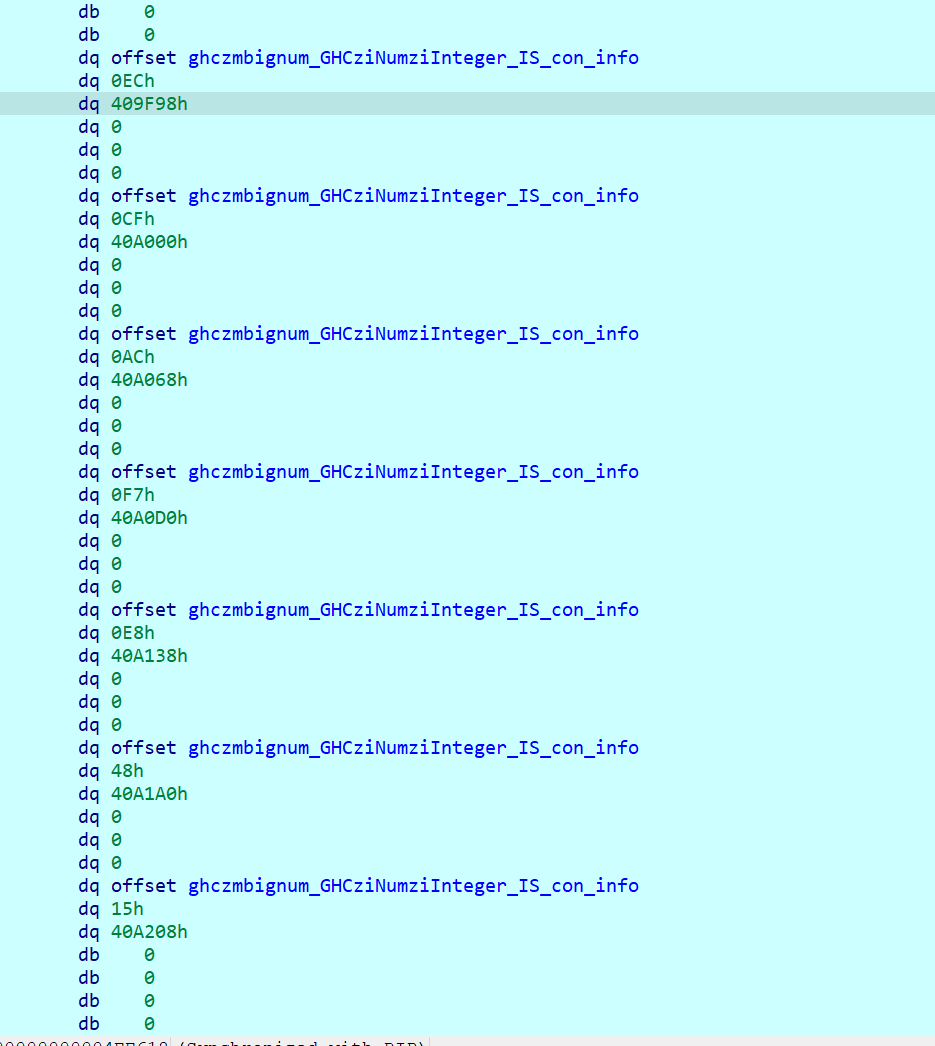
其中,第0个数据是头指针,第一个是密文数据,第二个指向的是一段代码,
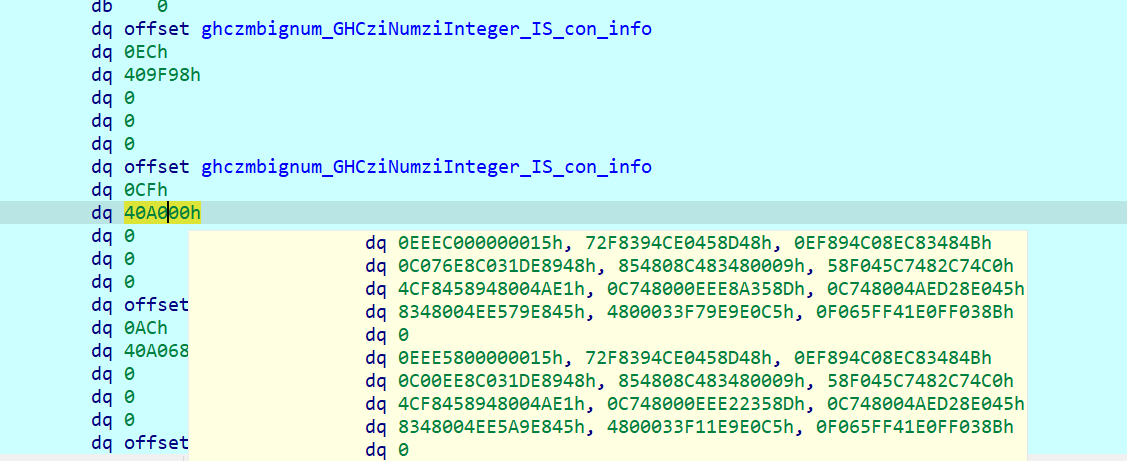
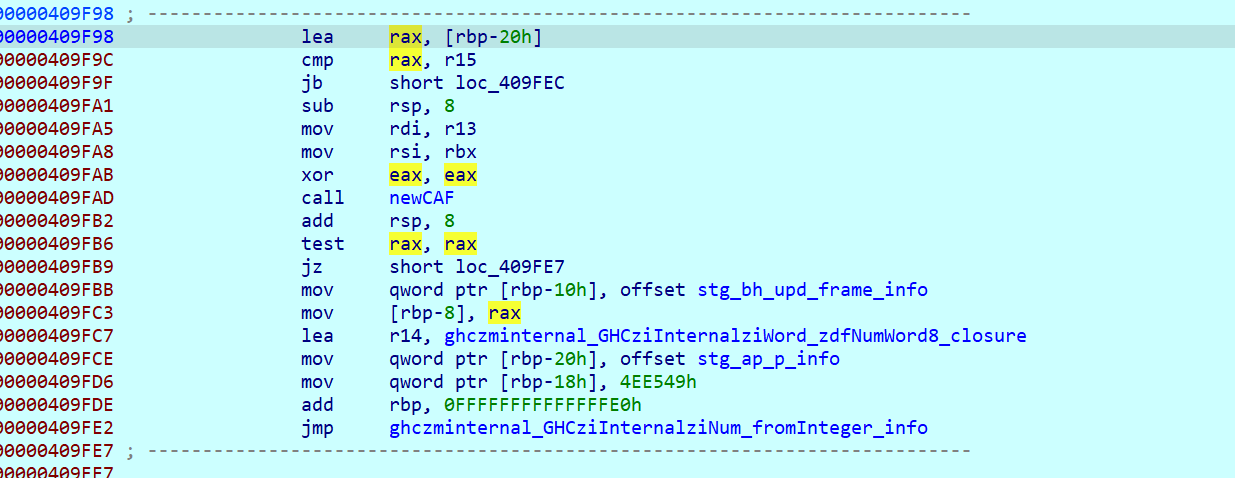
知道了RC4、密文和密钥就能解了
#include<stdio.h>
#include<string.h>
// 初始化 S 盒
void rc4_init(unsigned char *s, const unsigned char *key, int keylen) {
int i, j = 0;
for (i = 0; i < 256; ++i) {
s[i] = i;
}
for (i = 0; i < 256; ++i) {
j = (j + s[i] + key[i % keylen]) % 256;
// 交换 s[i] 和 s[j]
unsigned char tmp = s[i];
s[i] = s[j];
s[j] = tmp;
}
}
// 加密/解密数据
void rc4_crypt(unsigned char *s, unsigned char *data, int len) {
int i = 0, j = 0, t = 0;
for (int k = 0; k < len; k++) {
i = (i + 1) % 256;
j = (j + s[i]) % 256;
// 交换 s[i] 和 s[j]
unsigned char tmp = s[i];
s[i] = s[j];
s[j] = tmp;
t = (s[i] + s[j]) % 256;
data[k] ^= s[t];
}
}
int main(){
// char key[]={"Inkleqmp%q]Ncqv]Qwoogp"};
//
// for(int i=0;i<strlen(key);i++){
// key[i]^=2;
// }
// printf("%s",key);
// //Klingsor's_Last_Summer
// 密钥
const char *key = "Klingsor's_Last_Summer";
int keylen = strlen(key);
// 状态数组(S盒)
unsigned char s[256];
// 明/密文
unsigned char v4[] = {0xec, 0xcf, 0xac, 0xf7, 0xe8, 0x48, 0x15, 0x64
, 0x93, 0x40, 0xcf, 0x6a, 0x86, 0x52, 0xfc, 0xcc
, 0xf6, 0x86, 0x7a, 0x0d, 0x0d, 0x99, 0xda, 0xbc
, 0x36, 0xbb, 0xbf, 0x32, 0x8d, 0x27, 0x5d, 0xe8
, 0xbd, 0x93, 0x35, 0x31, 0x96, 0xc2, 0x9b, 0x76
, 0x4e, 0x6f, 0x26, 0x37, 0xfe, 0xe3, 0xea, 0x85
, 0xe6, 0xd0};
int len = sizeof(v4) / sizeof(v4[0]);
// 初始化 S 盒
rc4_init(s, (const unsigned char *)key, keylen);
// 加/解密数据
rc4_crypt(s, v4, len);
// 输出解密后的数据
for (int i = 0; i < len; i++) {
printf("%c", v4[i]^0x23);
}
printf("\n");
return 0;
}//Klingsor's_Last_Summer
//flag{Us3_H@sk3ll_t0_f1nd_th3_truth_1n_th1s_Summ3R}总结
函数式编程、惰性计算及存储方式。也算是初窥了Haskell逆向的冰⼭⼀⻆
逆向核心能力还不足,不能手撕汇编(哭

再引一下WP里的一句话
“于是我愿重⾛这条路,带着不同的感触,聆听⼩溪,凝视夜空,⼀次⼜⼀次。”
沉淀沉淀…
于是我愿重⾛这条路,带着不同的感触,聆听⼩溪,凝视夜空,⼀次⼜⼀次