
刷题笔记
1.python中,遇到元素是字符串类型的列表,要将其转成整数列表时,用以下代码
flag = [ord(c) for c in code]2.除了APKIDE能打开.apk文件外,还有JEB可以打开查看
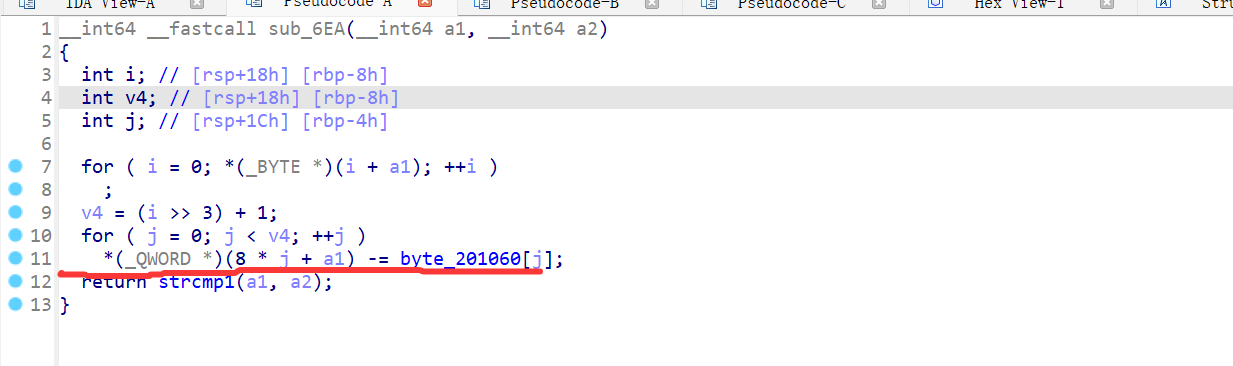
3.凯撒加密,右移m位时,解密代码为:
data[i]=(data[i]-'a'-m+26)%26+'a'//只考虑小写字母4.读html代码
<!DOCTYPE html />
<html>
<head>
<title>FLARE On 2017</title>
</head>
<body>
<input type="text" name="flag" id="flag" value="Enter the flag" />
<input type="button" id="prompt" value="Click to check the flag" />
<script type="text/javascript">
document.getElementById("prompt").onclick = function () {
var flag = document.getElementById("flag").value;
var rotFlag = flag.replace(/[a-zA-Z]/g, function (c) {
return String.fromCharCode((c <= "Z" ? 90 : 122) >= (c = c.charCodeAt(0) + 13) ? c : c - 26);
});
if ("[email protected]" == rotFlag) {
alert("Correct flag!");
} else {
alert("Incorrect flag, rot again");
}
};
</script>
</body>
</html>
var rotFlag = flag.replace(/[a-zA-Z]/g, function(c) { return String.fromCharCode((c <= "Z" ? 90 : 122) >= (c =
c.charCodeAt(0) + 13) ? c : c - 26); });
关键看这一句,
replace方法用于替换字符串中的某些部分。- 正则表达式
/[a-zA-Z]/g匹配字符串中所有的英文字母(包括大小写)。[a-zA-Z]:匹配任意一个英文字母(小写或大写)。g:表示全局匹配(即替换所有匹配到的字符,而不仅仅是第一个)
charCodeAt(0)返回字符的 Unicode 编码值。
c = c.charCodeAt(0) + 13- 将字符
c的编码值加上 13。 - 这一步实现了 ROT13 的核心操作:将字母向前移动 13 位。
(c <= "Z" ? 90 : 122)- 判断字符是否是大写字母:
- 如果
c是大写字母(即c <= "Z"),返回90(‘Z’ 的 Unicode 编码)。 - 如果
c是小写字母,返回122(‘z’ 的 Unicode 编码)。
- 如果
(c <= "Z" ? 90 : 122) >= c- 判断加了 13 后的编码值是否超出了字母范围:
- 如果没有超出范围(即仍在 ‘A’-‘Z’ 或 ‘a’-‘z’ 内),直接使用新的编码值。
- 如果超出了范围,则需要减去
26(字母表长度),回到正确的范围内。
String.fromCharCode(...)- 将计算后的编码值转换回字符。
5. CrackRTF
很棒的一道题,细看细看
int __cdecl main_0(int argc, const char **argv, const char **envp)
{
DWORD v3; // eax
DWORD v4; // eax
char Str[260]; // [esp+4Ch] [ebp-310h] BYREF
int v7; // [esp+150h] [ebp-20Ch]
char String1[260]; // [esp+154h] [ebp-208h] BYREF
char Destination[260]; // [esp+258h] [ebp-104h] BYREF
memset(Destination, 0, sizeof(Destination));
memset(String1, 0, sizeof(String1));
v7 = 0;
printf("pls input the first passwd(1): ");
scanf("%s", Destination);
if ( strlen(Destination) != 6 )
{
printf("Must be 6 characters!\n");
ExitProcess(0);
}
v7 = atoi(Destination); // str_to_long,比如"12345"->12345
if ( v7 < 100000 )
ExitProcess(0);
strcat(Destination, "@DBApp");
v3 = strlen(Destination);
j_sha1((BYTE *)Destination, v3, String1);
if ( !_strcmpi(String1, "6E32D0943418C2C33385BC35A1470250DD8923A9") )
{
printf("continue...\n\n");
printf("pls input the first passwd(2): ");
memset(Str, 0, sizeof(Str));
scanf("%s", Str);
if ( strlen(Str) != 6 )
{
printf("Must be 6 characters!\n");
ExitProcess(0);
}
strcat(Str, Destination);
memset(String1, 0, sizeof(String1));
v4 = strlen(Str);
j_md5((BYTE *)Str, v4, String1);
if ( !_strcmpi("27019e688a4e62a649fd99cadaafdb4e", String1) )
{
if ( !(unsigned __int8)sub_40100F((int)Str) )
{
printf("Error!!\n");
ExitProcess(0);
}
printf("bye ~~\n");
}
}
return 0;
}大概逻辑是先输入password1,对其进行验证后再输入password2然后验证。
atol(ASCII to Long)
查资料知这是#include<stdlib.h>头文件里的函数
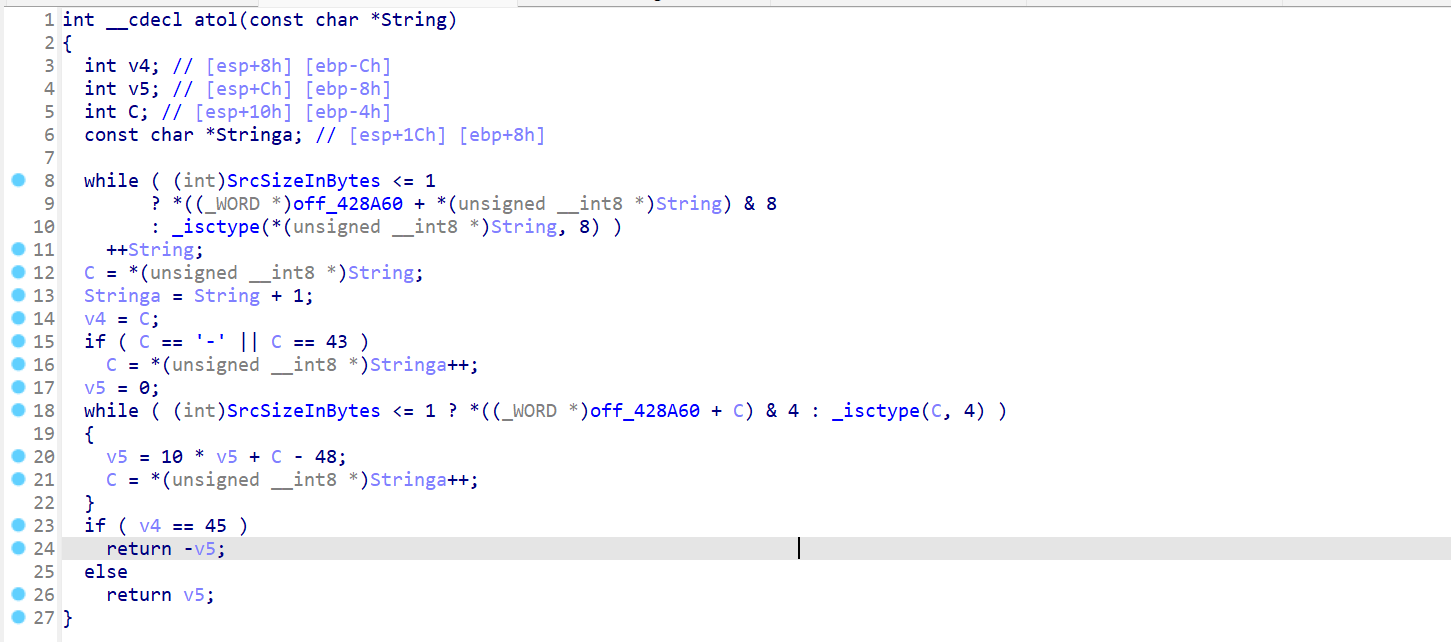
atoi()会扫描参数nptr字符串,跳过前面的空格字符,直到遇上数字或正负符号才开始做转换,而再遇到非数字或字符串结束时(‘\0’)才结束转换,并将结果返回
返回值:返回转换后的整型数。
//附加说明 atoi()与使用strtol(nptr,(char**)NULL,10);结果相同。_isctype()
是 Windows C 运行库(CRT)中的一个函数,用于检查字符类型(如字母、数字、大写、小写等)
int _isctype(int c, int type);//type:_ALPHA、_DIGIT、_UPPER、_LOWER等
/*返回值
非零值(true):表示 c 符合指定的 type 类型。
0(false):表示 c 不属于 指定的类型。
*/第一个加密函数:j_sha1((BYTE *)Destination, v3, String1);函数名是分析后添上的

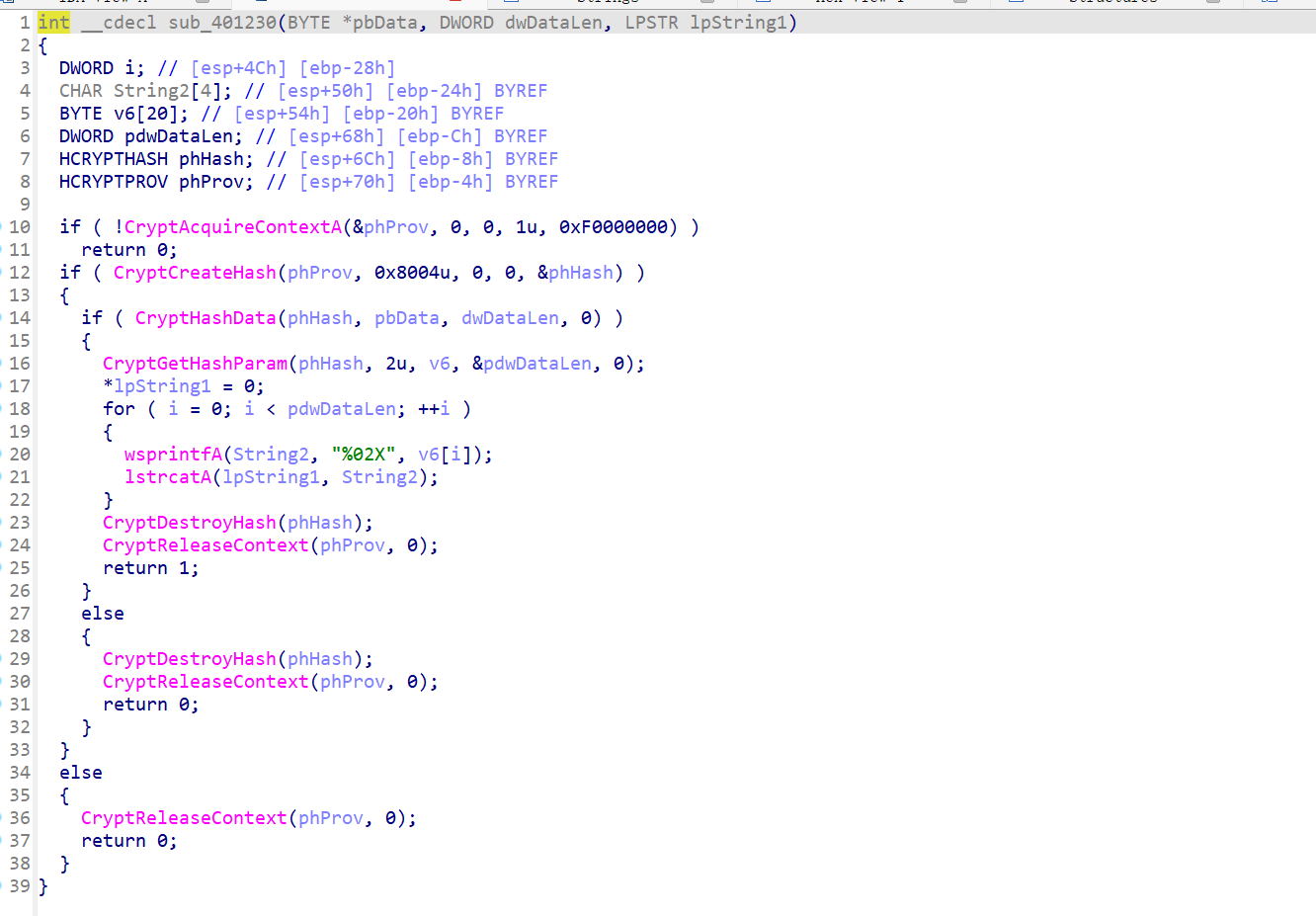
CryptAcquireContextA
用于获取特定密钥容器的句柄
BOOL CryptAcquireContextA(
[out] HCRYPTPROV *phProv,
[in] LPCSTR szContainer,
[in] LPCSTR szProvider,
[in] DWORD dwProvType,
[in] DWORD dwFlags
);CryptAcquireContextA(&phProv, 0, 0, 1u, 0xF0000000)//CryptCreateHash
创建哈希对象
BOOL CryptCreateHash(
[in] HCRYPTPROV hProv,
[in] ALG_ID Algid,
[in] HCRYPTKEY hKey,
[in] DWORD dwFlags,
[out] HCRYPTHASH *phHash
);CryptCreateHash(phProv, 0x8004u, 0, 0, &phHash)ALG_ID=0x8004,说明是SHA1哈希算法

其他参照ALG_ID (Wincrypt.h) - Win32 应用 |Microsoft 学习↗
CryptHashData
计算哈希
CryptHashData(phHash, pbData, dwDataLen, 0)将
pbData数据输入哈希对象phHash进行计算。dwDataLen指定输入数据的长度。
CryptGetHashParam
获取哈希结果。
CryptGetHashParam(phHash, 2u, v6, &pdwDataLen, 0);2u表示获取 实际哈希值(即 HP_HASHVAL)。v6存储计算出的 MD5 哈希值(MD5 长度固定为 16 字节)。pdwDataLen存储哈希值的 实际长度(应为 16)。
*lpString1 = 0;//先清空
for ( i = 0; i < pdwDataLen; ++i )
{/*遍历 v6 中的每个字节,将其转换为 十六进制字符串(%02X)。
使用 lstrcatA 逐步拼接到 lpString1,得到最终的哈希字符串。*/
wsprintfA(String2, "%02X", v6[i]);
lstrcatA(lpString1, String2);
}所以这个函数返回的passwod1+"@DBApp"的SHA1哈希值
爆破求解,因为atol函数要求输入内容必须是数字或者’+‘或’-’
又要求转换成整型后要大于等于100000,爆破即可
import hashlib
def sha1_to_hex(data):
# 创建一个 SHA1 哈希对象
sha1_hash = hashlib.sha1()
# 更新哈希对象的数据
sha1_hash.update(data)
# 获取哈希值的字节表示
hash_bytes = sha1_hash.digest()
# 将每个字节转换为两位的十六进制字符串,并拼接成最终结果
hex_result = ''.join(f"{byte:02X}" for byte in hash_bytes)
return hex_result
passwd1=""
for i1 in range(49,58):
for i2 in range(48,58):
for i3 in range(48,58):
for i4 in range(48,58):
for i5 in range(48,58):
for i6 in range(48,58):
passwd1=chr(i1)+chr(i2)+chr(i3)+chr(i4)+chr(i5)+chr(i6)
passwd1+="@DBApp"
result = sha1_to_hex(passwd1.encode())
if result == '6E32D0943418C2C33385BC35A1470250DD8923A9':
print(passwd1)
#123321@DBApp
'''
其实代码可以写得好看些:
import hashlib
string='@DBApp'
for i in range(100000,999999):
flag=str(i)+string
x = hashlib.sha1(flag.encode("utf8"))
y = x.hexdigest()
if "6e32d0943418c2c33385bc35a1470250dd8923a9" == y:
print(flag)
break
'''往下看第二部分
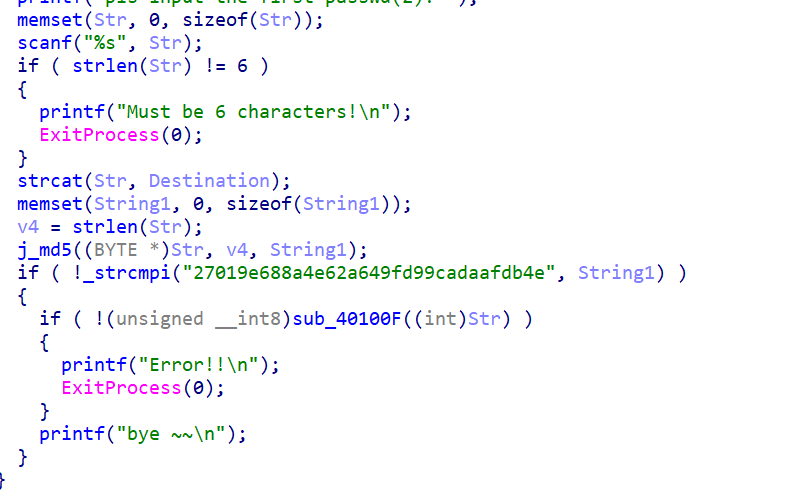
获取passwod2后将前面共12个字符的字符串拼接到Str后面,再进行加密验证,这次是md5,函数和前面的几乎一样,唯一区别就是ALG_ID变成了0x8003,查资料知是md5哈希
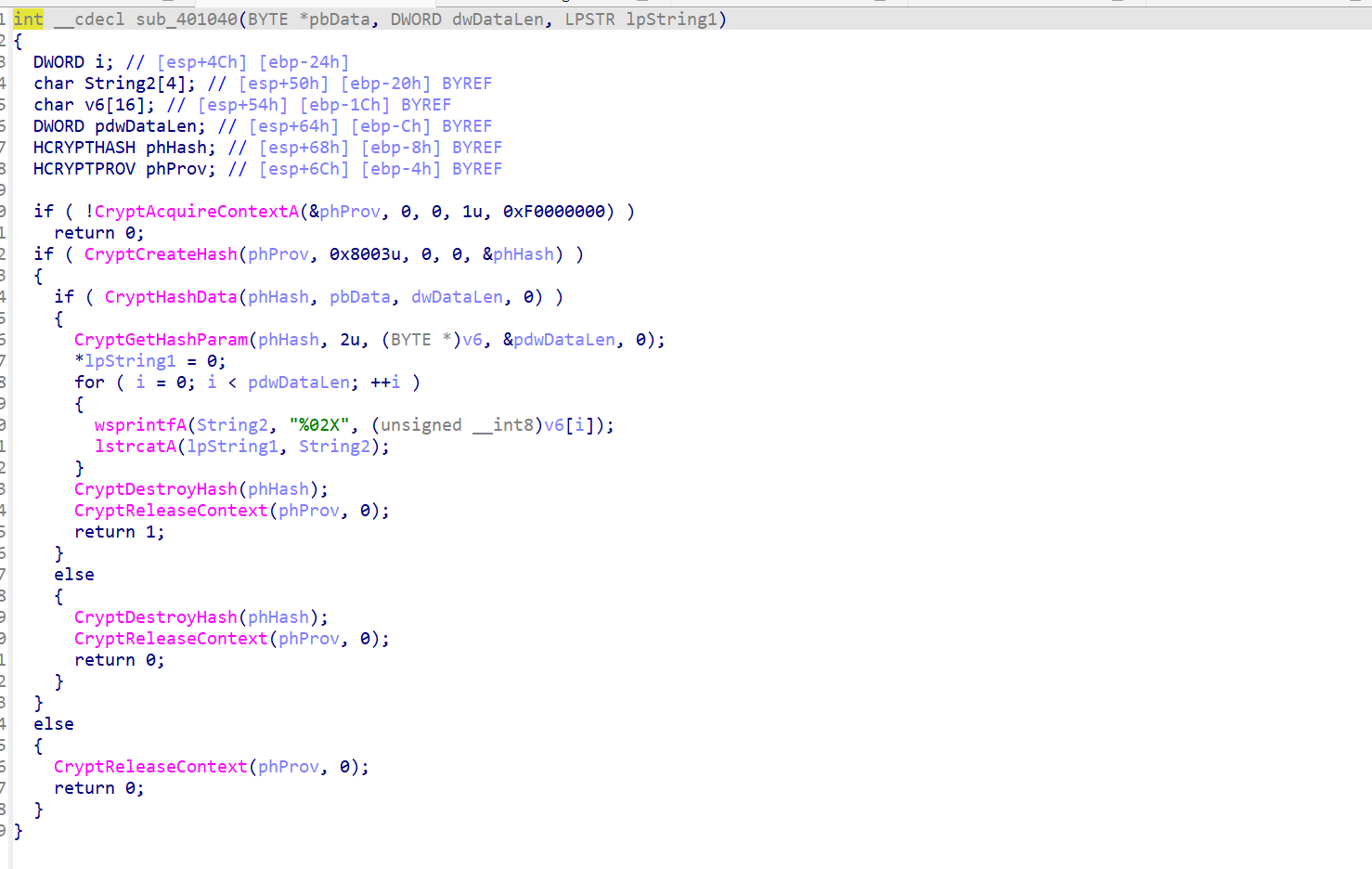

但是缺少信息,不可能爆破(因为至少需要10000^3的时间复杂度)
看sub_40100F((int)Str)
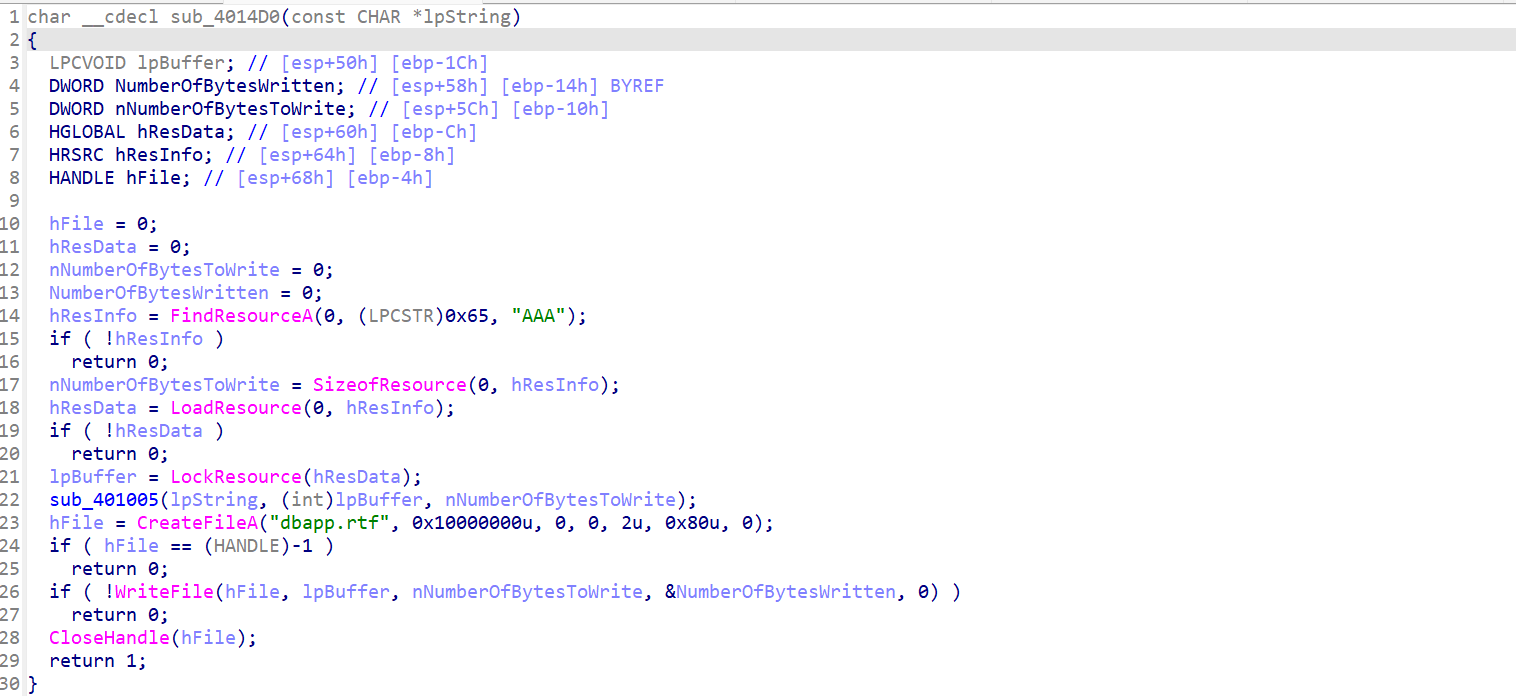
FindResourceA(0,(LPCSTR)0x65,"AAA");:从资源段加载资源(标识符 0x65,类型 "AAA")
SizeofResource(0, hResInfo);:获取资源大小,返回 DWORD 类型的字节数。
LoadResource(0, hResInfo):加载资源,返回 HGLOBAL 句柄。
LockResource(hResData):锁定资源,返回指向资源数据的指针 文件写入:
hFile = CreateFileA("dbapp.rtf", 0x10000000u, 0, 0, 2u, 0x80u, 0);
//GENERIC_WRITE (0x10000000):以写入模式打开文件。
//CREATE_ALWAYS (2u):始终创建新文件(如果已存在则覆盖)。
//FILE_ATTRIBUTE_NORMAL (0x80):普通文件,无特殊属性
WriteFile(hFile, lpBuffer, nNumberOfBytesToWrite, &NumberOfBytesWritten, 0);
//WriteFile 将资源数据写入 dbapp.rtf 文件。
CloseHandle(hFile);
//关闭文件句柄,防止资源泄漏。大概意思就是会创建一个.rtf文件并往里面写一些数据,具体内容由lpBuffer确定,,但至少我们知道**.rtf文件头**。
再看
sub_401005(lpString, (int)lpBuffer, nNumberOfBytesToWrite);它是唯一使用了传入的Str的函数
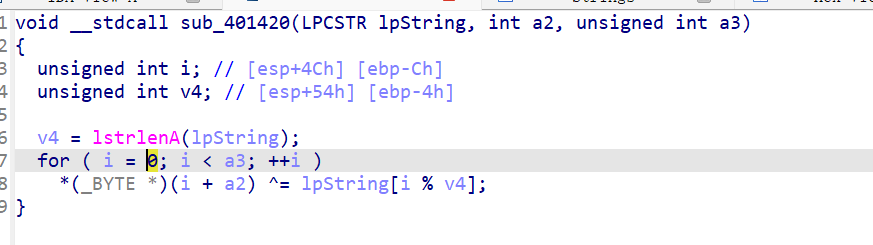
循环异或,把要写入的内容与lpString[i]即Str[i]循环异或,异或后的值被写到.rtf文件里。
整理一下
- Str长为18位,前六位未知
- .rtf文件的前六位为
"{\rtf1\" - 使用
ResourceHacker工具找到资源文件”AAA”,前六位为:0x05, 0x7D, 0x41, 0x15, 0x26, 0x01

只需将.rtf文件前六位与”AAA”前六位异或就拿到了passwod2
str=r"{\rtf1"
source=[0x05, 0x7D, 0x41, 0x15, 0x26, 0x01 ]
for i in range(6):
print(chr(source[i]^ord(str[i])),end="")
#~!3a@0运行程序,输入passwod1和passwod2后会在当前目录下生成一个.rtf文件,里面有flag
6.go
ida运行脚本快捷键:alt+f7或者file+Script
7. 线程
先看代码
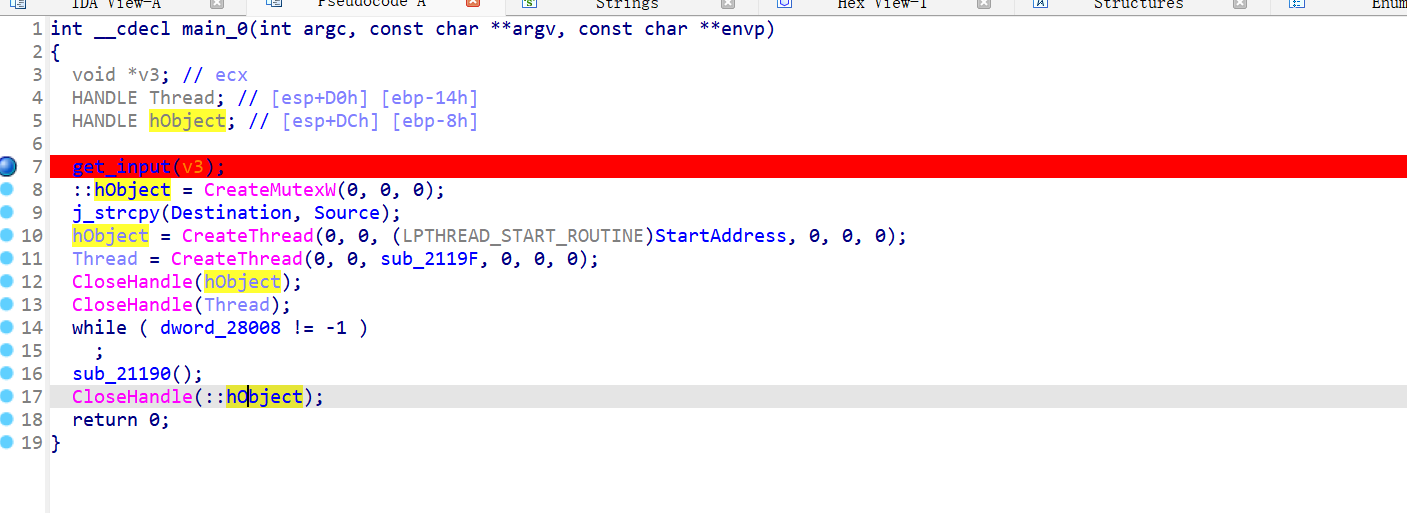
创建互斥体
::hObject = CreateMutexW(0, 0, 0);
/*
第一个参数为安全属性,传入 0 表示使用默认安全属性。
第二个参数为初始拥有状态,传入 0 表示互斥体未被任何线程拥有。
第三个参数为互斥体名称,传入 0 表示创建一个未命名的互斥体。
返回值是互斥体句柄,存储在全局变量 ::hObject 中。
*/创建线程
hObject = CreateThread(0, 0, StartAddress, 0, 0, 0);
Thread = CreateThread(0, 0, sub_41119F, 0, 0, 0);
/*
第一个参数为线程安全属性,传入 0 表示使用默认安全属性。
第二个参数为线程堆栈大小,传入 0 表示使用默认堆栈大小。
第三个参数为线程函数的地址:
第一个线程的入口点是 StartAddress。
第二个线程的入口点是 sub_41119F。
第四个参数为传递给线程函数的参数,传入 0 表示无参数。
第五个参数为线程创建标志,传入 0 表示线程立即运行。
第六个参数为线程标识符,传入 0 表示不关心线程ID。
返回值是线程句柄,分别存储在 hObject 和 Thread 中。
*/sleep调用
线程1入口点:
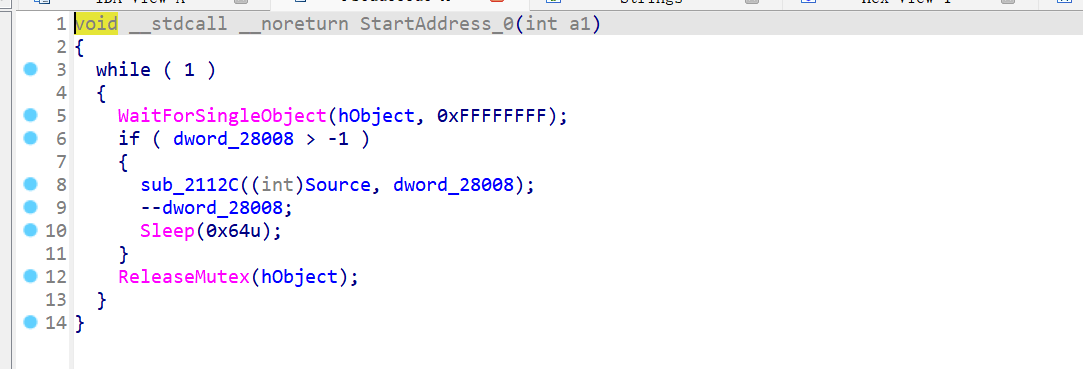
线程2入口点
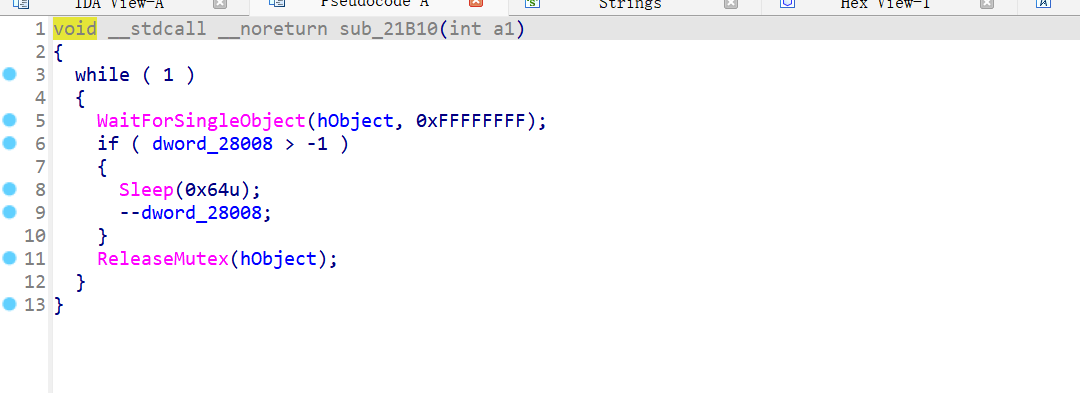
可以发现他们共享全局变量dword_28008并对其进行读取修改操作,并通过Sleep(0x64u)降低了线程的运行频率,从而减少了并发冲突的可能性。
互斥体(hObject):
WaitForSingleObject(hObject, 0xFFFFFFFF);//线程尝试获取互斥体的所有权。如果互斥体已经被其他线程占用,则当前线程会阻塞,直到互斥体可用。
// 访问和修改 dword_28008
ReleaseMutex(hObject);//线程释放互斥体,允许其他线程获取所有权。确保在同一时刻只有一个线程能够访问和修改 dword_28008,从而避免了竞态条件的发生。
因此,代码中两个线程会轮流执行,对于StartAddress来说,每次运行相当于dword_28008减了2.
8. c++读代码
名称重整:C++的函数名经过name mangling,IDA尝试还原但不够完美,如refptr__ZSt4cout表示std::cout的引用。
模板实例化:很多函数带有模板参数,如std::operator<<<std::char_traits<char>>。
读懂代码
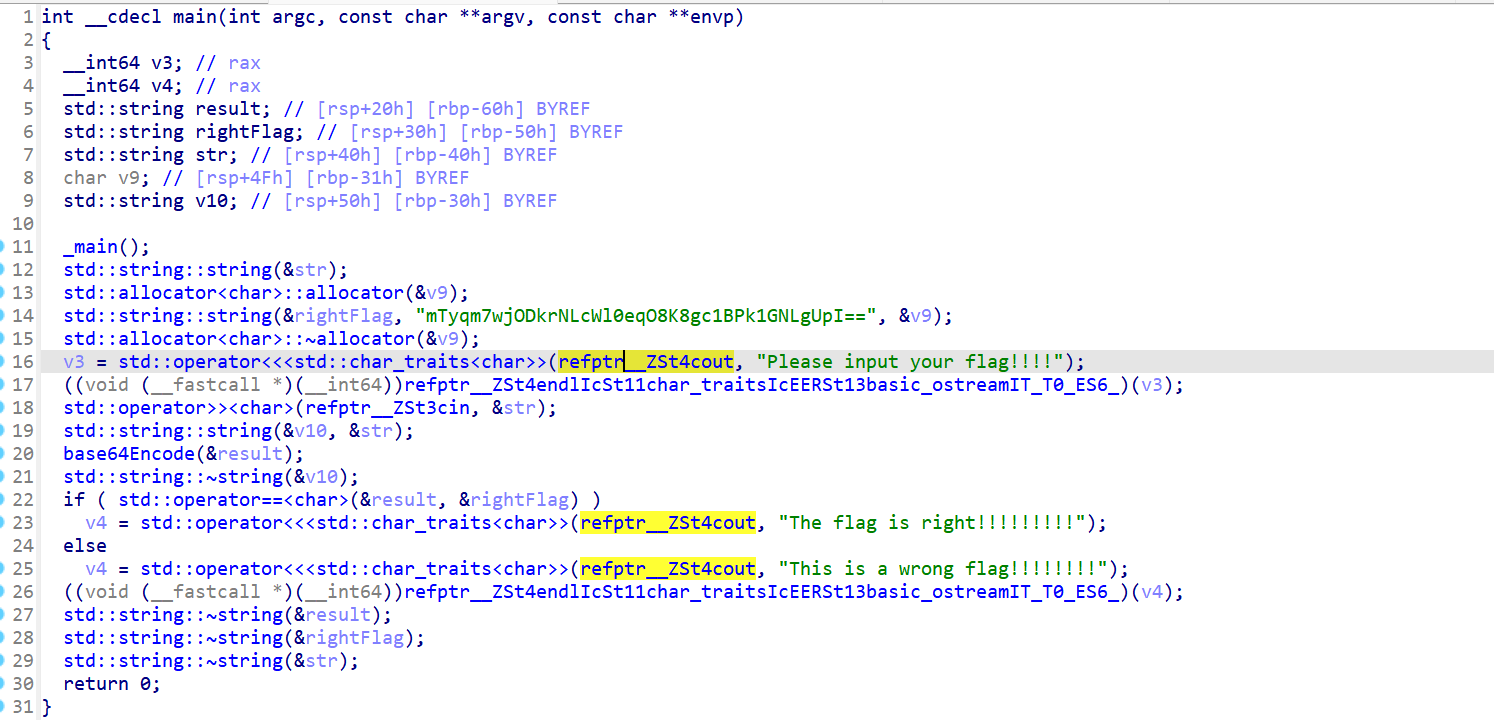
字符串操作
std::string::string(&str);
std::allocator<char>::allocator(&v9);
std::string::string(&rightFlag, "mTyqm7wj00krNLcMlQeqO8K8gciBPk16NLgbIz=", &v9);- 构造一个空字符串str
- 创建一个allocator对象
- 构造rightFlag字符串,初始化为”mTyqm7wj00krNLcMlQeqO8K8gciBPk16NLgbIz=“
输出提示
std::allocator<char>::allocator(&v9);
v = std::operator<<<std::char_traits<char>>(refptr__ZSt4cout, "Please input your flag!!!!!");
((void(__fastcall *)(__int64))refptr__ZSt4endlISSt1Idhar_traitsIcEERSt13basic_ostreamIT_TO_E56_)(v3);- 再次创建allocator(可能是冗余代码)
- 输出提示信息”Please input your flag!!!!!”
- 输出换行符(std::endl)
输入处理
std::operator>><char>(refptr__ZSt5cin, &str);
std::string::string(&v10, &str);
base64Encode(&result);- 从标准输入读取字符串到str
- 构造一个新字符串v10(可能是IDA生成的临时变量名)
- 对输入字符串进行base64编码,结果存储在result中
这段代码的核心逻辑是:读取用户输入,进行base64编码,然后与预存的base64字符串比较,验证输入的flag是否正确。
9 修改数据类型
ida有时候将变量类型识别为 _int64时会有一些问题,视情况改成int可以修正
例如,这是int下的
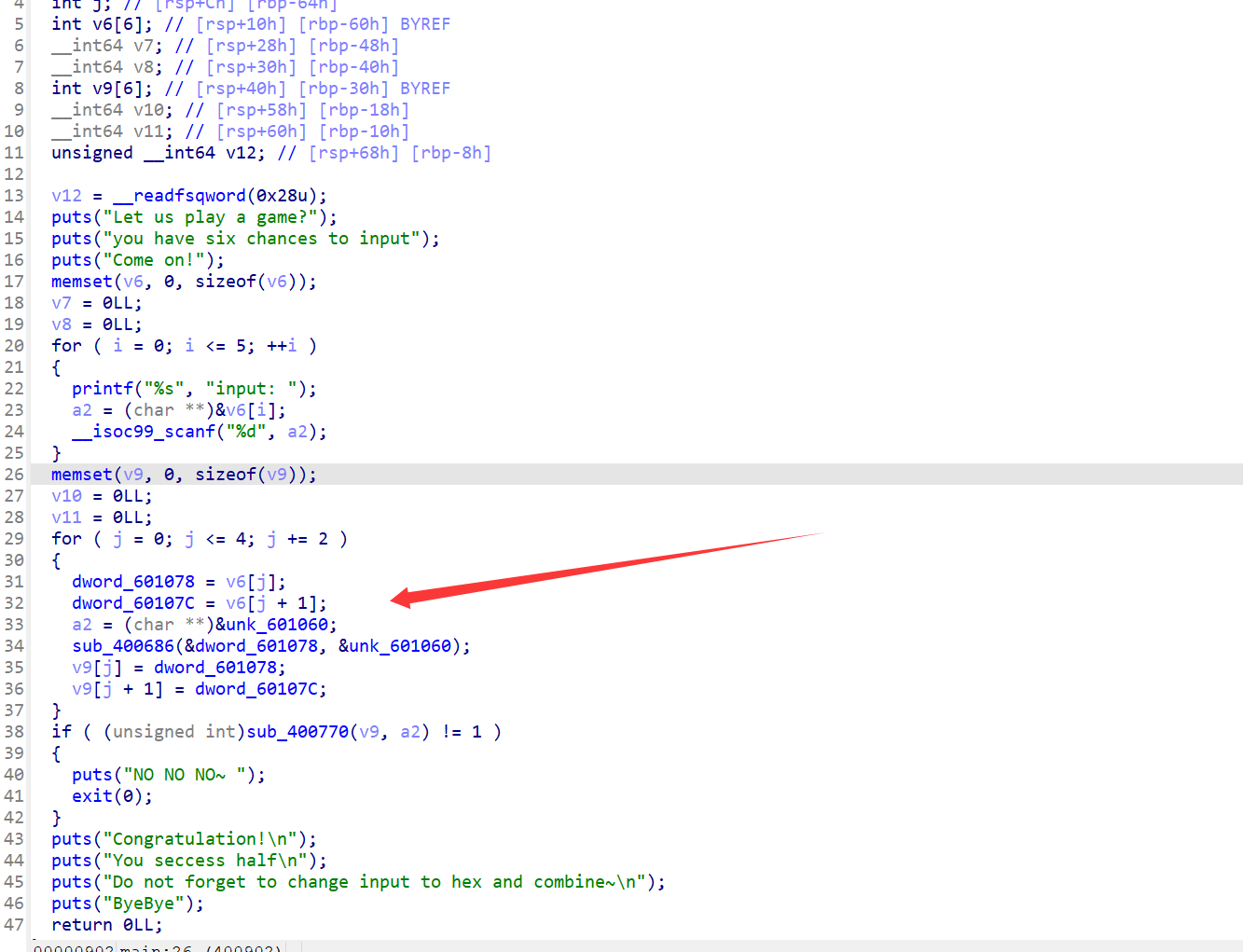
改了后如下
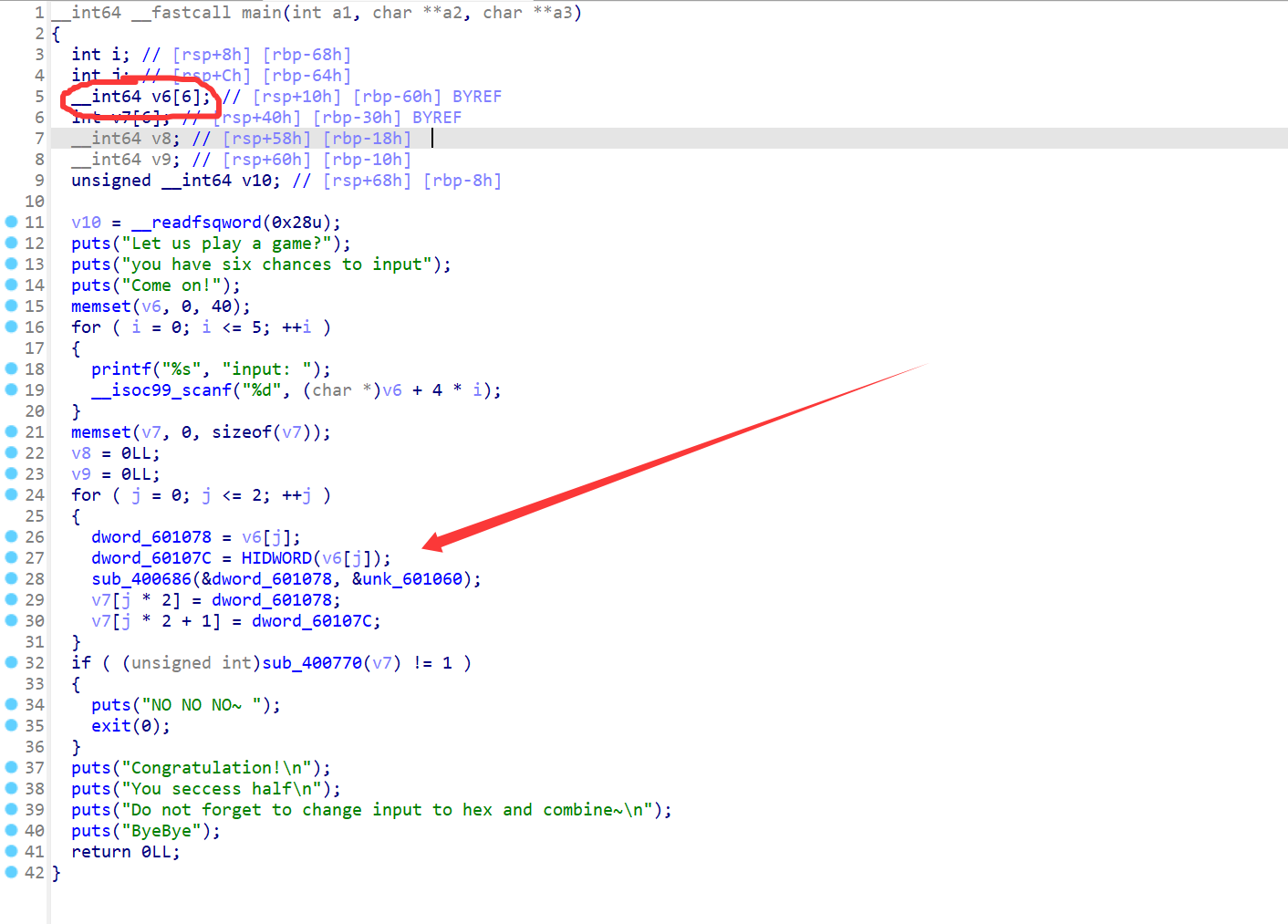
很难看而且容易误解,要注意!
10.字符串相加
如图
已知减法运算后对应的字符串是zer0pts{********CENSORED********}
若要还原,不能直接对每个字节进行一对一还原,因为在减法时可能会出现减不够的情况,对应还原过程也就是可能会发生溢出,使下一位值**+1**,所以写脚本时要考虑这种情况
#include<stdio.h>
#include<string.h>
int main(){
unsigned char flag[] =
{
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x42, 0x09,
0x4A, 0x49, 0x35, 0x43, 0x0A, 0x41, 0xF0, 0x19, 0xE6, 0x0B,
0xF5, 0xF2, 0x0E, 0x0B, 0x2B, 0x28, 0x35, 0x4A, 0x06, 0x3A,
0x0A, 0x4F, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00
};
char str[]={"zer0pts{********CENSORED********}"};
int temp;
for(int i=0;i<strlen(str);i++){
temp=str[i]+flag[i];
if(temp>0xff){//注意这里!~
str[i+1]+=1;
}
str[i]=temp&0xff;
}
printf("%s",str);
//zer0pts{l3ts_m4k3_4_DETOUR_t0d4y}
return 0;
}11.CrackMe
好题,细细剖析

已知用户名是’welcomebeijing’
丢ida里分析
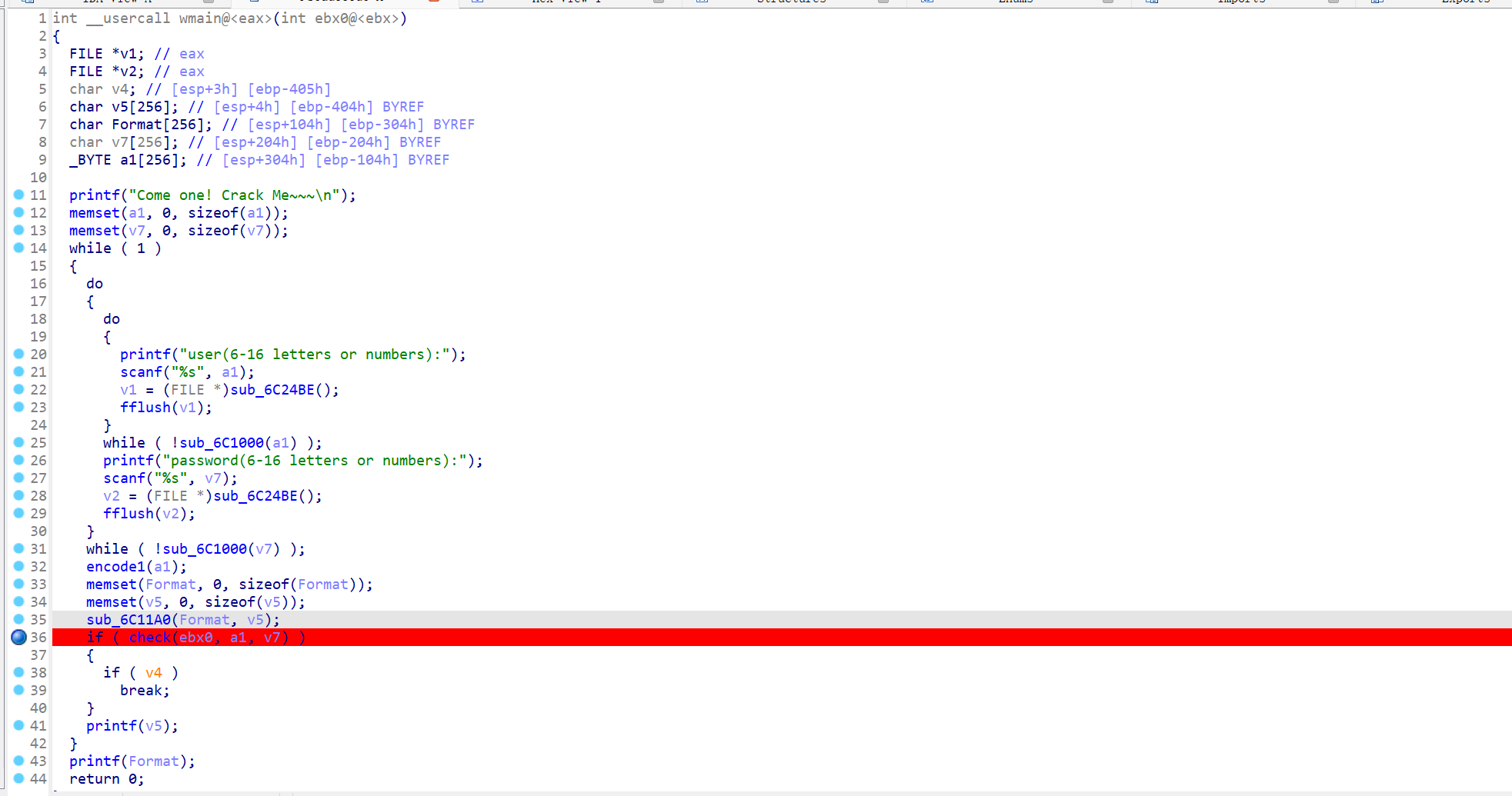
逻辑大概是输入用户名和密码,然后用输入的用户名进行一些初始化操作,最后验证密码
username已知,前面初始化的内容可以通过动调拿到,因此直接看check
bool __usercall check@<al>(int ebx0@<ebx>, char *a2, const char *arg4)
{
int v4; // [esp+18h] [ebp-22Ch]
int v5; // [esp+1Ch] [ebp-228h]
int a3; // [esp+28h] [ebp-21Ch]
unsigned int i; // [esp+30h] [ebp-214h]
char v8; // [esp+36h] [ebp-20Eh]
char v9; // [esp+37h] [ebp-20Dh]
char v10; // [esp+38h] [ebp-20Ch]
unsigned __int8 v11; // [esp+39h] [ebp-20Bh]
unsigned __int8 v12; // [esp+3Ah] [ebp-20Ah]
char v13; // [esp+3Bh] [ebp-209h]
unsigned int v14; // [esp+3Ch] [ebp-208h] BYREF
char v15; // [esp+40h] [ebp-204h] BYREF
char v16[255]; // [esp+41h] [ebp-203h] BYREF
char a1[256]; // [esp+140h] [ebp-104h] BYREF
v5 = 0;
a3 = 0;
v12 = 0;
v11 = 0;
memset(a1, 0, sizeof(a1));
v15 = 0;
memset(v16, 0, sizeof(v16));
v10 = 0;
i = 0;
v4 = 0;
while ( i < strlen(arg4) )
{
if ( isdigit(arg4[i]) )
{
v9 = arg4[i] - '0';
}
else if ( isxdigit(arg4[i]) )
{
if ( *((_DWORD *)NtCurrentPeb()->ProcessHeap + 3) != 2 )
arg4[i] = '"';
v9 = (arg4[i] | 0x20) - 'W';
}
else
{
v9 = ((arg4[i] | 0x20) - 'a') % 6 + 10;
}
__rdtsc();
__rdtsc();
v10 = v9 + 16 * v10;
if ( !((int)(i + 1) % 2) )
{
v16[v4++ - 1] = v10;
ebx0 = v4;
v10 = 0;
}
++i;
}
while ( a3 < 8 )
{
v11 += s[++v12];
v13 = s[v12];
v8 = s[v11];
s[v11] = v13;
s[v12] = v8;
if ( (NtCurrentPeb()->NtGlobalFlag & 0x70) != 0 )
v13 = v11 + v12;
a1[a3] = s[(unsigned __int8)(v8 + v13)] ^ v16[v5 - 1];
if ( (unsigned __int8)*(_DWORD *)&NtCurrentPeb()->BeingDebugged )
{
v11 = 0xAD;
v12 = 0x2B;
}
sub_6C1710((int)a1, a2, a3++);
v5 = a3;
if ( a3 >= (unsigned int)(&v16[strlen(&v15)] - v16) )
v5 = 0;
}
v14 = 0;
sub_6C1470(ebx0, a1, &v14); // key
return v14 == 0xAB94;
}注意反调试
if((NtCurrentPeb()->NtGlobalFlag & 0x70) != 0)
//NtCurrentPeb()返回指向当前进程的PEB结构的指针
//NtGlobalFlag存储了一系列标志位,用于控制调试行为。
/*
0x70 是一个掩码,表示只关心 NtGlobalFlag 的第 4、5、6 位(从最低位开始计数为第 0 位)。
这些位通常与堆调试相关,具体如下:
第 4 位 (0x10):FLG_HEAP_ENABLE_TAIL_CHECK
第 5 位 (0x20):FLG_HEAP_ENABLE_FREE_CHECK
第 6 位 (0x40):FLG_HEAP_VALIDATE_PARAMETERS
*/
__rdtsc();
__rdtsc();
/*
__rdtsc() 是一个汇编指令,用于读取时间戳计数器(Time Stamp Counter)。每次调用都会返回 CPU 的时钟周期数。
这里连续调用了两次 __rdtsc(),可能是为了引入一定的延迟,或者是为了干扰反调试工具的检测。
*/
这个表达式通常用于检测当前进程是否运行在调试模式下,或者是否启用了某些调试功能
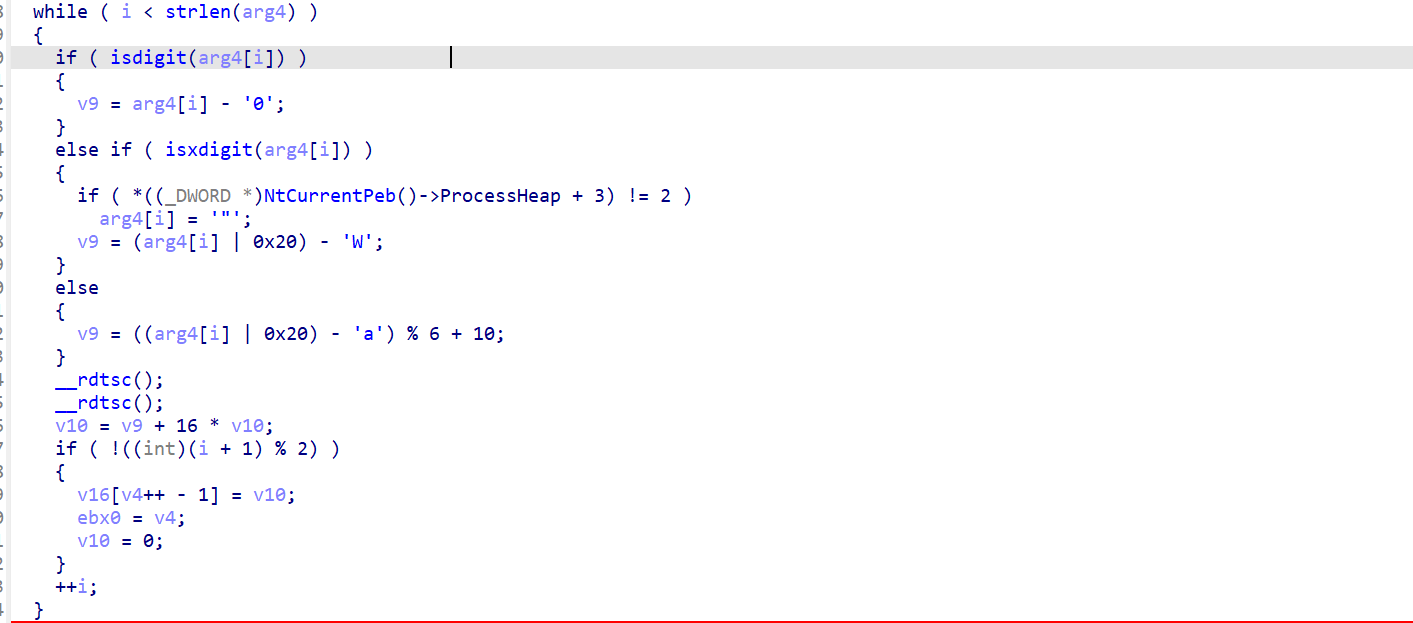
这部分是对password进行转换,如果是’0''9’,则转成对应的09,isxdigit()用于判断数据是否为十六进制形式,如果是,则转成对应的值,例如’A’--->10,‘b’—>11;如果是另外的字母,则在abcde的基础上转成对应的数值,例如’G’--->16,‘h’--->17
这里关注一下
v9 = (arg4[i] | 0x20) - 'W';
v9 = ((arg4[i] | 0x20) - 'a') % 6 + 10;先回到ASCII 编码的特点:
#大写字母 A-Z 的编码范围是 0x41 - 0x5A。
#小写字母 a-z 的编码范围是 0x61 - 0x7A。
#差值为0x20=32
'A'(大写):01000001(0x41)
'a'(小写):01100001(0x61)
#将第 5 位设置为 1,就可以将大写字母转换为对应的小写字母。
#0x20: 00100000
#将字符的 ASCII 值与 0x20 进行按位或运算,可以确保第 5 位被设置为 1,从而将大写字母转换为小写字母。注意’W’=87,‘a’=97
因此将小写字母减去87刚好对应十六进制下从a开始对应的值(1035),又通过%6和后面的+10保证值在1015
所以这段代码的功能是将输入转成对应的十进制数,然后逐字节进行拼接
例如:1234ghi--->1234abc,将值存在v16里进入后序的处理
再看下面

倒着看,先看sub_6C1470(ebx0, a1, &v14);,这里要求处理后的v14必须为0xAB94
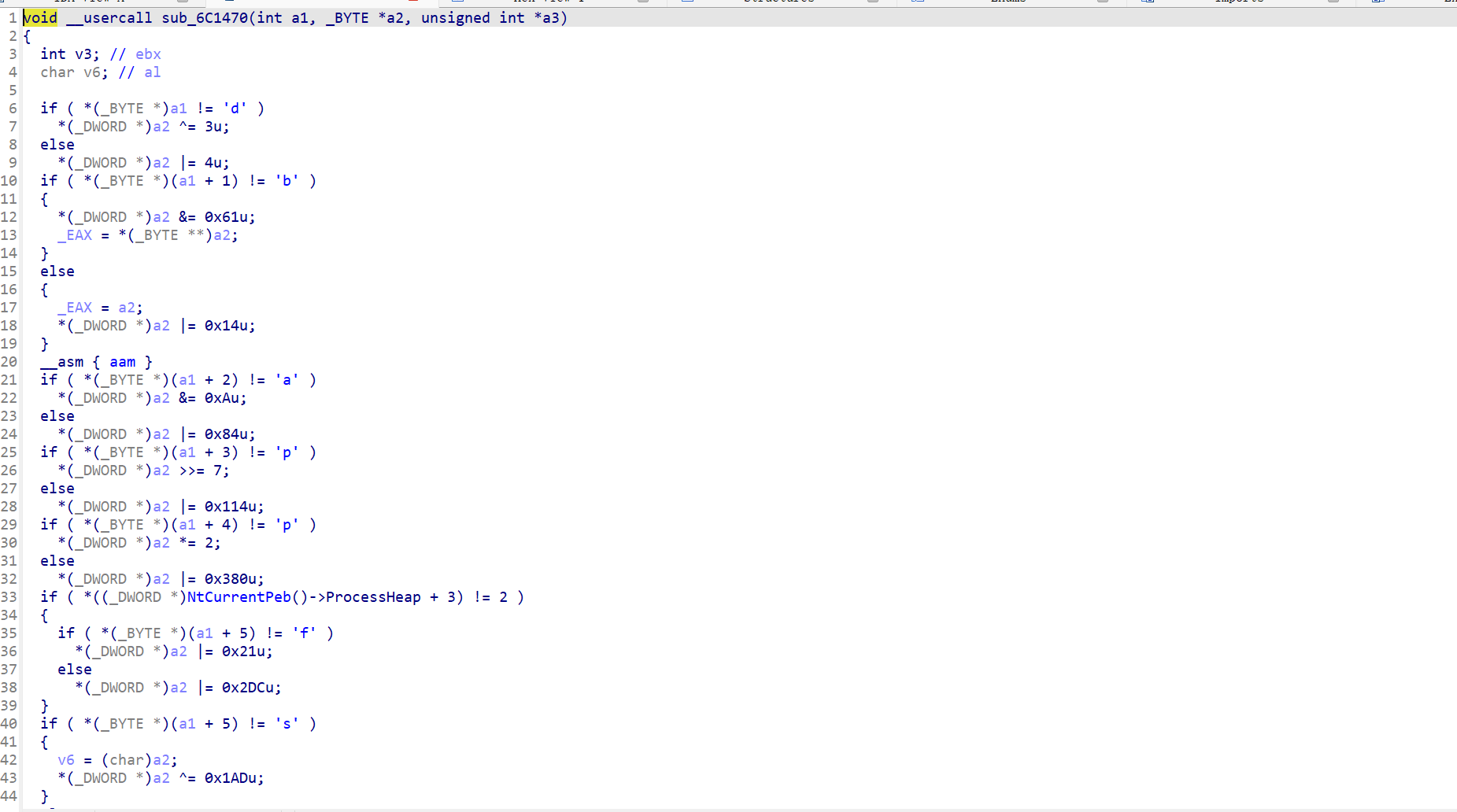

显然,这些!=处的值就是a1[i]的值,注意a1+5有两种情况,但是其中一种是调试状态下考虑的,这明显是反调试手段,直接略过,得到a1:dbappsec
退出来往上看sub_6C1710((int)a1, a2, a3++);
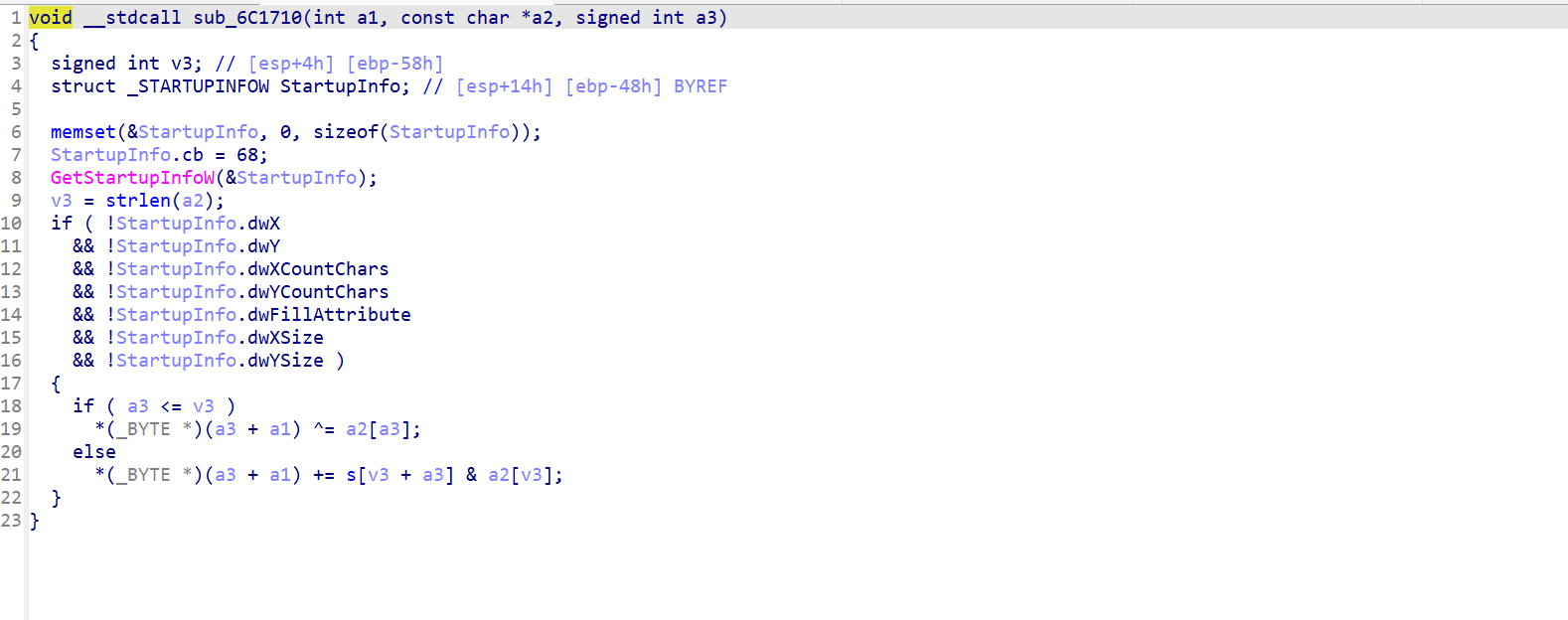
异或加密,不用考虑else
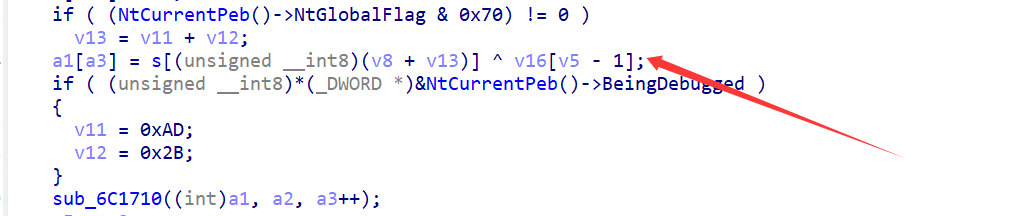
显然a1我们已经能拿到数据了,容易推断出v16就是flag,关键要拿到参与异或的s[v8+v13],其前后还有反调试,上OD。
先通过ida找到这段代码对应的汇编以及相对地址:
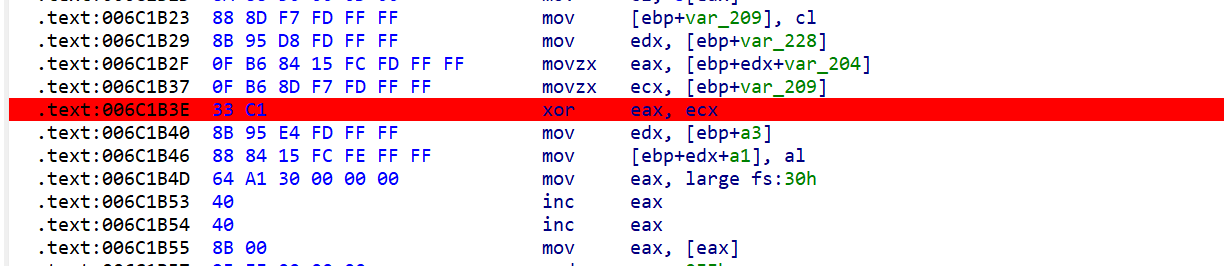
在OD中找到对应的汇编代码并下断点

通过在ida简单调试可知我们要的值在ecx里,dump出来后异或一下就是flag
#include<stdio.h>
int main(){
char key[]={"dbappsec"};
unsigned char str[]={0x2A,0xd7,0x92,0xe9,0x53,0xe2,0xc4,0xcd};
for(int i=0;i<8;i++){
printf("%x",str[i]^key[i]);
}
//4eb5f3992391a1ae
return 0;
}这道题让我印象最深的是OD可以直接无视前面那么多反调试手段,很好奇为什么,有没有大佬指点一下()
12.[ACTF新生赛2020]SoulLike
爆破的手法,学习一下
主逻辑很简单,获取输入并检查是不是actf{}的格式,最后对里面的内容进行验证
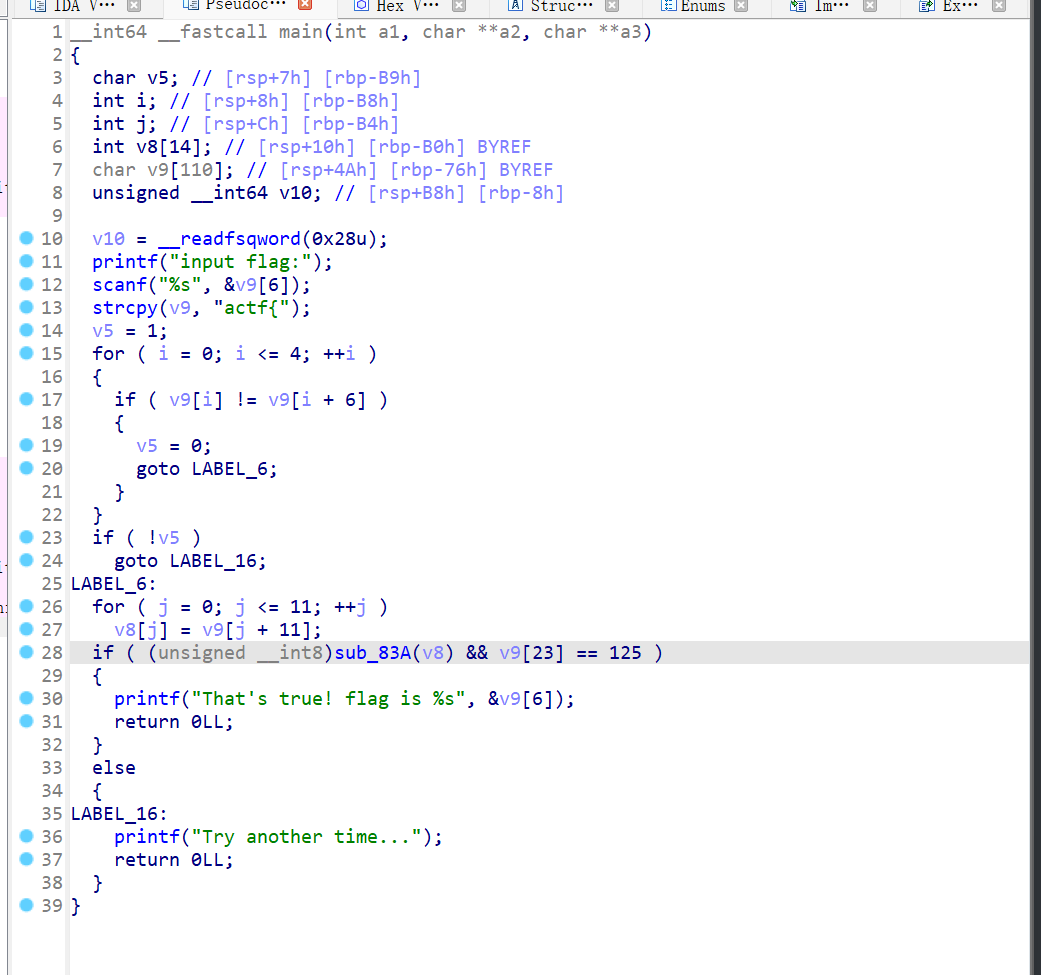
但是sub_83A函数里面的代码量很大,有3000行,验证逻辑是很清晰的。
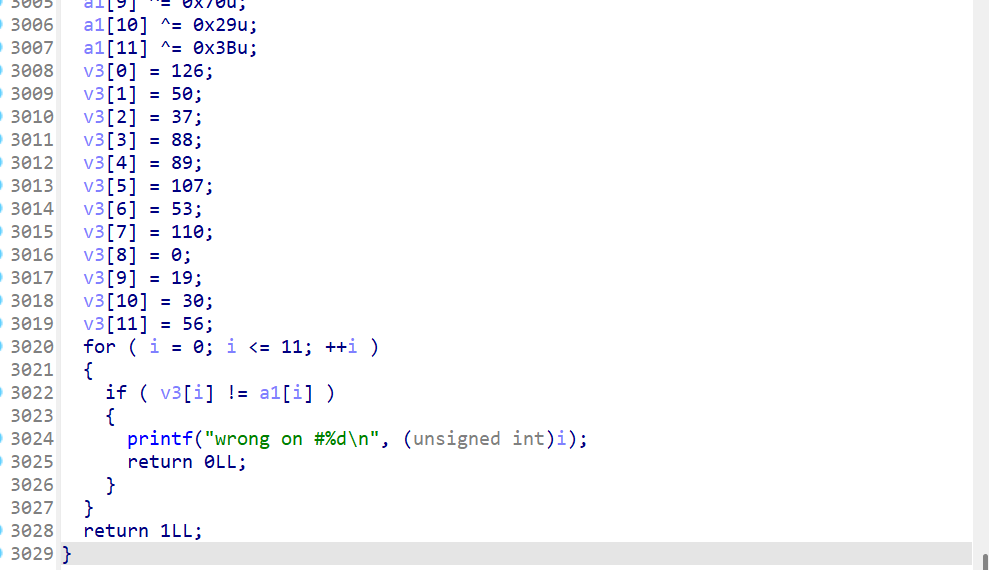
已知长度为12位,那么可以进行爆破,并且输出的错误信息还友好的给出了当前错误的位置。
exp:
from pwn import *
import re
context.log_level = 'debug'
# p = process('./pwn')
flag = "actf{"
pos = 0
while True:
for ch in range(32,128):
p = process('./SoulLike')
ch = chr(ch)
payload = flag + ch
print(flag)
# p.sendlineafter("input flag:",payload)
p.sendline(payload)
r = str(p.recvline())
num = re.findall("\d+",r)[0]#从字符串 r 中提取第一个匹配的数字
num = int(num)
# print(num)
if num == pos:
print('No')
elif num==pos+1:
print(r)
flag += ch
pos += 1
p.close()
p.close()
if pos>11:
break
print(flag)
#actf{b0Nf|Re_LiT!}13. java反编译
一种方案是用IDEA,打开文件所在文件夹,然后右键.jar文件然后添加到库就能看到了
14. 赛博厨子
怎么熟练地使用cyberchef呢?
15. .NET,C#逆向
丢dnspy,可以下断点调试,另外unity游戏题,即使是安卓的也可以找到assets\bin\Data\Managed\Assembly-CSharp.dll用dnspy分析
16. firmware(!!!)(专题文章待写)
固件分析题型,需要掌握常规分析流程和了解常见报错问题(这里只从做题人的角度写方法,具体基础知识弄个文章专门讨论)
首先会给一个二进制文件(.bin),里面存了固件的各种文件,所以要用binwalk -e提取它们

binwalk -e pack.bin#这里改了下文件名报错1
权限问题。

这个错误的意思是 binwalk 在提取固件 (pack.bin) 时,为了安全考虑,默认不会以当前用户权限执行第三方提取工具。
解决办法是加上 --run-as=root 参数,并确保 binwalk 以 root 运行。
我已经是root用户,因此换以下指令:
binwalk -e --run-as=root pack.bin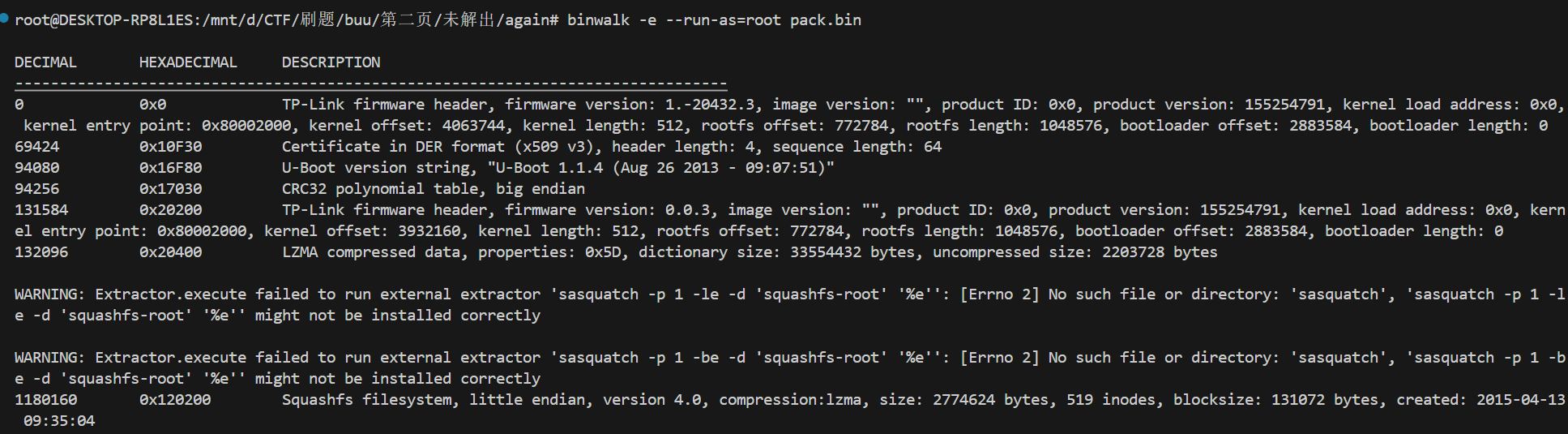
从提取信息可以看出:
TP-Link 固件头
U-Boot 引导加载器
LZMA 压缩数据
SquashFS 文件系统
直接贴别人的解释squashfs文件系统 - yooooooo - 博客园↗

报错2
提取完成后,发现还有报错(如上图)
WARNING: Extractor.execute failed to run external extractor 'sasquatch -p 1 -le -d 'squashfs-root' '%e'': [Errno 2] No such file or directory: 'sasquatch'说明 binwalk 试图解压 SquashFS 文件系统时找不到 sasquatch 工具,导致解包失败。
我们打开解包后生成的文件夹

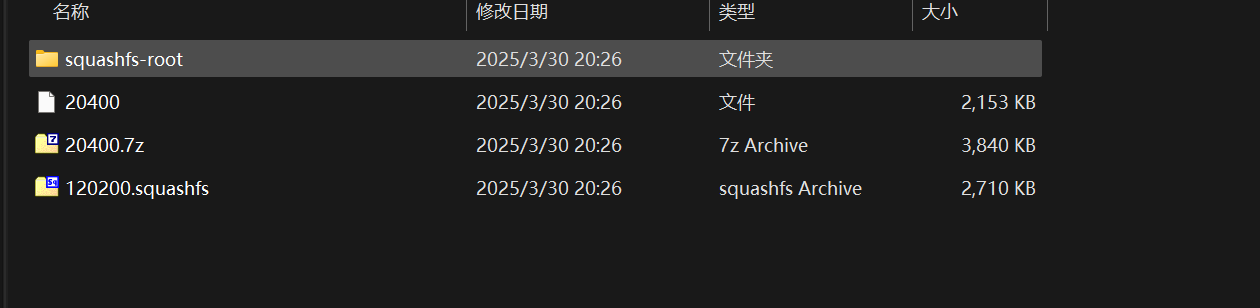
其中由于解包失败,导致squashfs-root文件夹是空的,需要手动使用工具对120200.squashfs进行解包
工具采用firmware-mod-kit,安装教程参考2022年 firmware-mod-kit 配置方法 - Carykd - 博客园↗
#适用于Ubuntu 20.04之后
sudo apt-get install git build-essential zlib1g-dev liblzma-dev python3-magic autoconf python-is-python3
#解决安装liblzma-dev的问题
sudo apt-get install aptitude#使用包管理工具aptitude下载
sudo aptitude install liblzma-dev#有了aptitude,我们再下载其他的就方便很多了。
#配好环境后下载firmware
git clone https://github.com/rampageX/firmware-mod-kit.git下载后能直接用(很不错,之前安装一个还要我手动make,结果报一大堆错,到处查资料也没弄好。哭)
此题使用以下功能:
./unsquashfs_all.sh 120200.squashfs#解包,文件需要使用对应的路径提取后在当前工作目录下生成目标文件夹
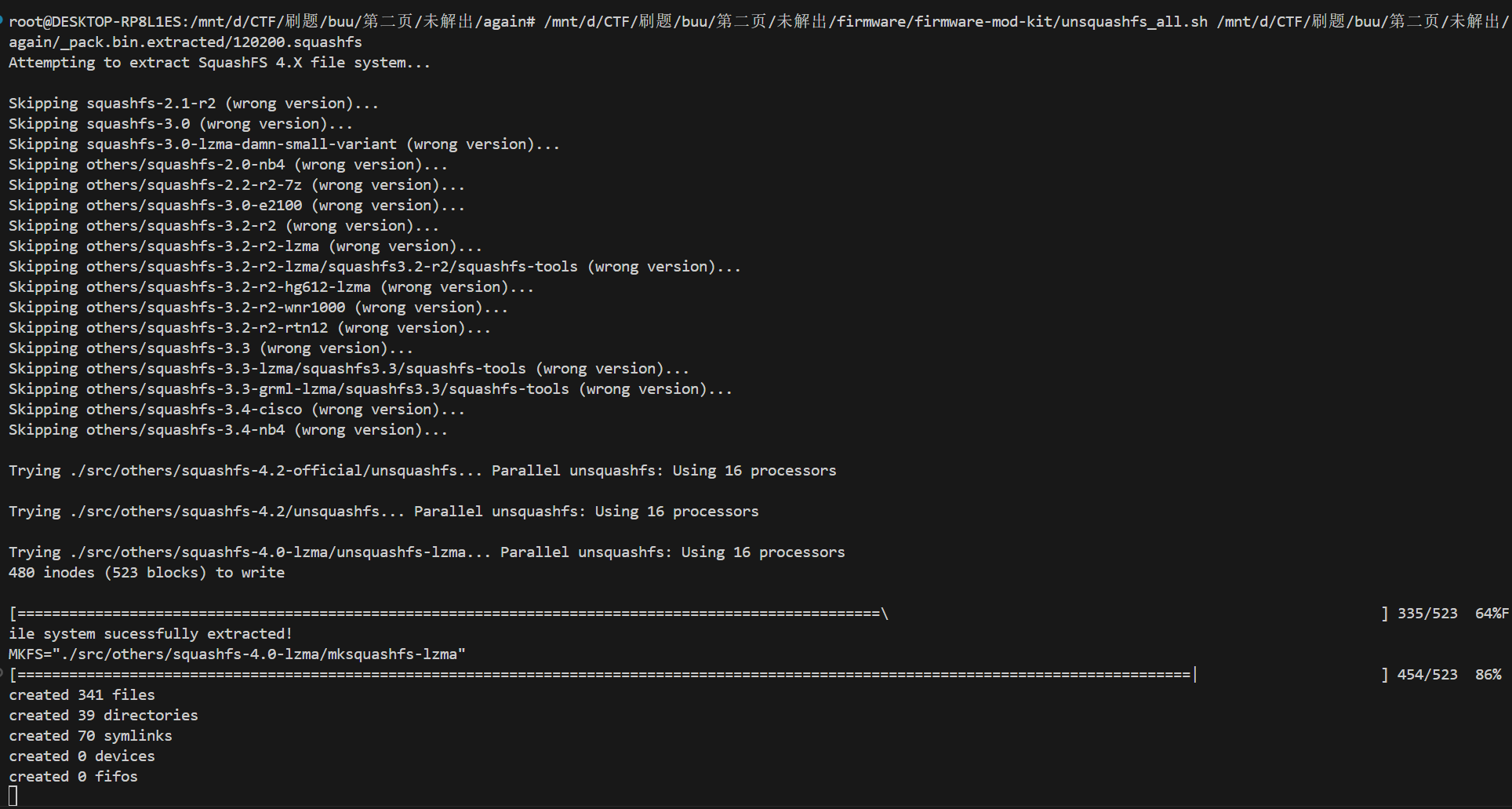

找到tmp/目录下的文件就可以用ida分析了。

流程差不多就这样
报错3
注意,在使用wsl下的Linux执行最后一步操作时,一定要保证firmware-mod-kit和目标文件以及当前工作目录在同一个环境下,就是说要么都在Linux的目录里,要么都在windows的目录里,不能分开,会导致解包失败(亲测~)
参考资料:
squashfs文件系统 - yooooooo - 博客园↗
2022年 firmware-mod-kit 配置方法 - Carykd - 博客园↗
firmware-mod-kit工具安装和使用说明-CSDN博客↗
17..NET逆向
一个扫雷题,有897个雷,找到3个非雷的位置就算过关

看别人的wp知道可以开透视挂和无敌挂,但是我最开始是去找map,直接找非雷位置的坐标
这里判断方法,检查当前选中的位置是否是雷,如果是就执行流程
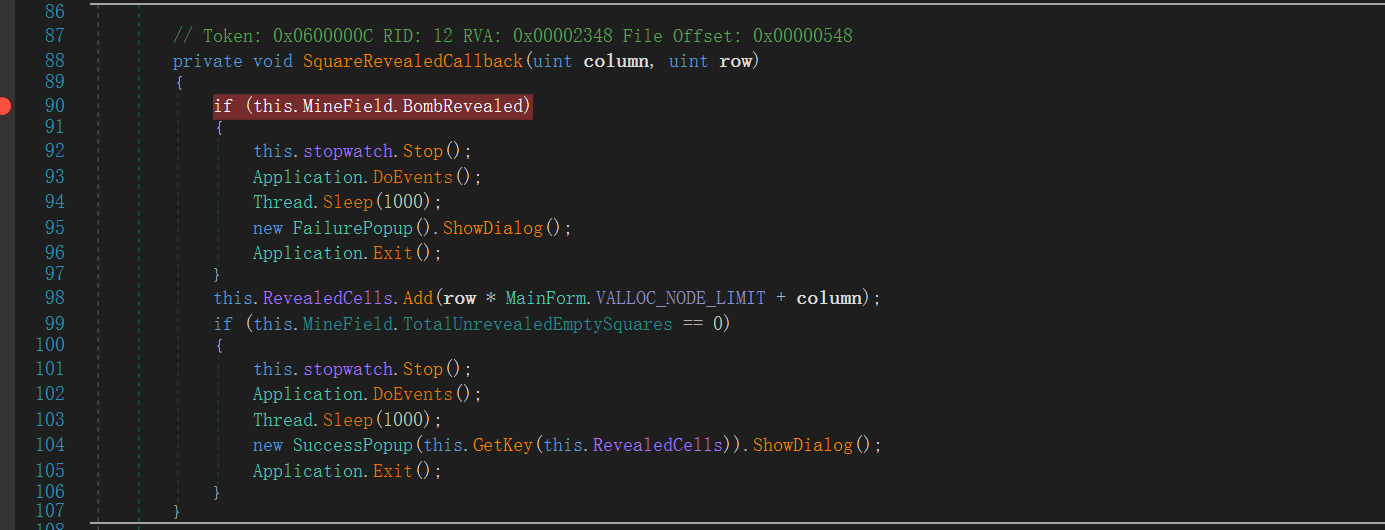
在这下个断点,然后查看此时的map就可以了
另外的方法参考(o゚v゚)ノ Hi - re | buuctf逆向刷题之Ultimate MineSweeper全分析↗
收获:
- dnspy查找快捷键:ctrl+shift+k(再也不用到处找了
- dnspy可以编辑方法,然后重新编译达到hook的效果,最后可以应用修改到一个新的exe上,和
ida的apply patch to很像
18.XXTEA
python代码:
import struct
_DELTA = 0x9E3779B9
def _long2str(v, w):
n = (len(v) - 1) << 2
if w:
m = v[-1]
if (m < n - 3) or (m > n): return b''
n = m
s = struct.pack('<%iL' % len(v), *v)
return s[:n] if w else s
def _str2long(s, w):
n = len(s)
m = (4 - (n & 3) & 3) + n
s = s.ljust(m, b"\0") # 确保是 bytes 类型
v = list(struct.unpack('<%iL' % (m >> 2), s))
if w: v.append(n)
return v
def encrypt(data, key):
if not data: return data
v = _str2long(data, True)
k = _str2long(key.ljust(16, b"\0"), False)
n = len(v) - 1
z = v[n]
y = v[0]
sum = 0
q = 6 + 52 // (n + 1)
while q > 0:
sum = (sum + _DELTA) & 0xffffffff
e = sum >> 2 & 3
for p in range(n):
y = v[p + 1]
v[p] = (v[p] + ((z >> 5 ^ y << 2) + (y >> 3 ^ z << 4) ^ (sum ^ y) + (k[p & 3 ^ e] ^ z))) & 0xffffffff
z = v[p]
y = v[0]
v[n] = (v[n] + ((z >> 5 ^ y << 2) + (y >> 3 ^ z << 4) ^ (sum ^ y) + (k[n & 3 ^ e] ^ z))) & 0xffffffff
z = v[n]
q -= 1
return _long2str(v, False)
def decrypt(data, key):
if not data: return data
v = _str2long(data, False)
k = _str2long(key.ljust(16, b"\0"), False)
n = len(v) - 1
z = v[n]
y = v[0]
q = 6 + 52 // (n + 1)
sum = (q * _DELTA) & 0xffffffff
while sum != 0:
e = sum >> 2 & 3
for p in range(n, 0, -1):
z = v[p - 1]
v[p] = (v[p] - ((z >> 5 ^ y << 2) + (y >> 3 ^ z << 4) ^ (sum ^ y) + (k[p & 3 ^ e] ^ z))) & 0xffffffff
y = v[p]
z = v[n]
v[0] = (v[0] - ((z >> 5 ^ y << 2) + (y >> 3 ^ z << 4) ^ (sum ^ y) + (k[0 & 3 ^ e] ^ z))) & 0xffffffff
y = v[0]
sum = (sum - _DELTA) & 0xffffffff
return _long2str(v, True)
if __name__ == "__main__":
key = b"flag" # Python3 需要 bytes
data1 = [0xbc, 0xa5, 0xce, 0x40, 0xf4, 0xb2, 0xb2, 0xe7,
0xa9, 0x12, 0x9d, 0x12, 0xae, 0x10, 0xc8, 0x5b,
0x3d, 0xd7, 0x06, 0x1d, 0xdc, 0x70, 0xf8, 0xdc]
s = bytes(data1) # 直接转换为 bytes
s = decrypt(s, key)
print(repr(s))19.c/c++符号修饰
名字修饰
名字修饰(name decoration),也称为名字重整、名字改编(name mangling),是现代计算机程序设计语言的编译器用于解决由于程序实体的名字必须唯一而导致的问题的一种技术。
直接贴别人的解释

函数签名(Function Sginature)
函数签名包含了一个函数的信息,包括函数名、参数类型、所在类、名称空间及其他信息。 比如: int func(int x)的函数签名为:int func(int) 每个函数签名对应一个修饰后的名字。
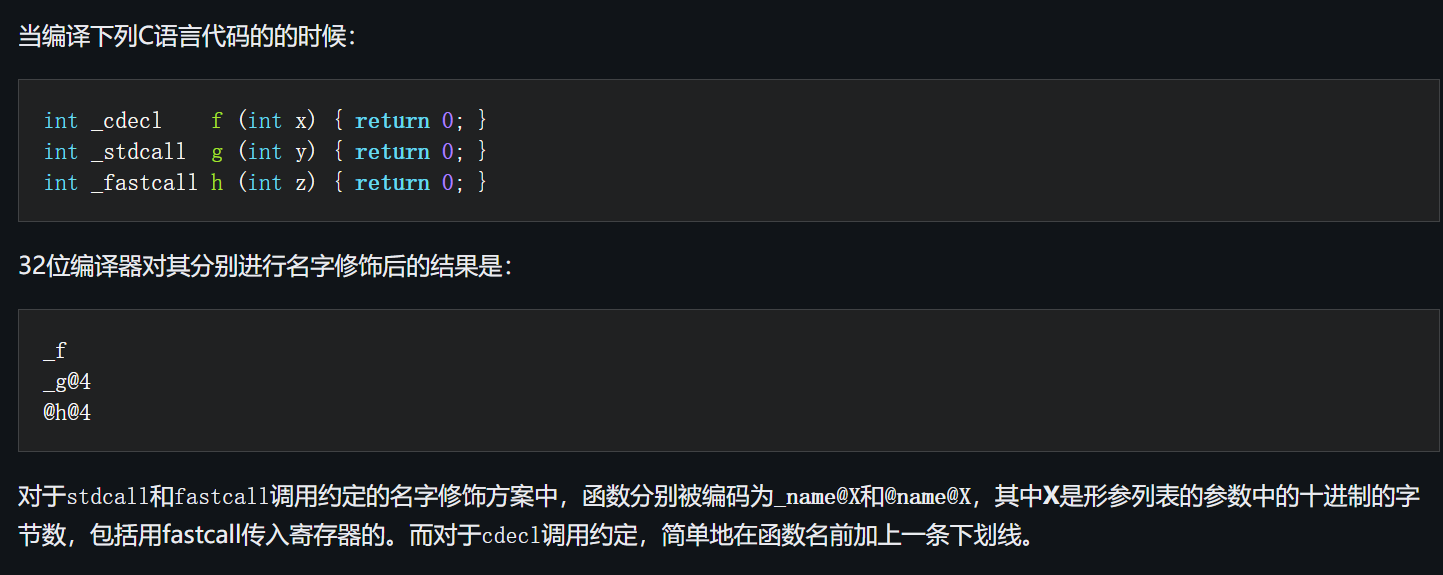
c语言名字修饰
名字修饰方案由微软公司首创,目前已经被许多其它的编译器非正式采用,例如Digital Mars公司、Borland公司以及Windows移植版的GNU GCC。该方案甚至被其它语言采用,例如Pascal↗、D语言↗、Delphi↗、Fortran↗和C#↗。这允许用这此语言写的子程序使用不同于自身默认的调用约定来调用或被调用于已存在的Windows库。
c++符号修饰
C++编译器是名字修饰使用得出名的编译器。第一个C++编译器的实现是翻译成C语言源代码,以便于让C编译器编译成目标代码。正因如此,符号名必须遵守C语言的标识符规则。直至后来,能直接产生机器语言或汇编语言的编译器出现了以后,系统的链接器也是基本上不支持C++的符号的,所以仍然需要名字修饰。
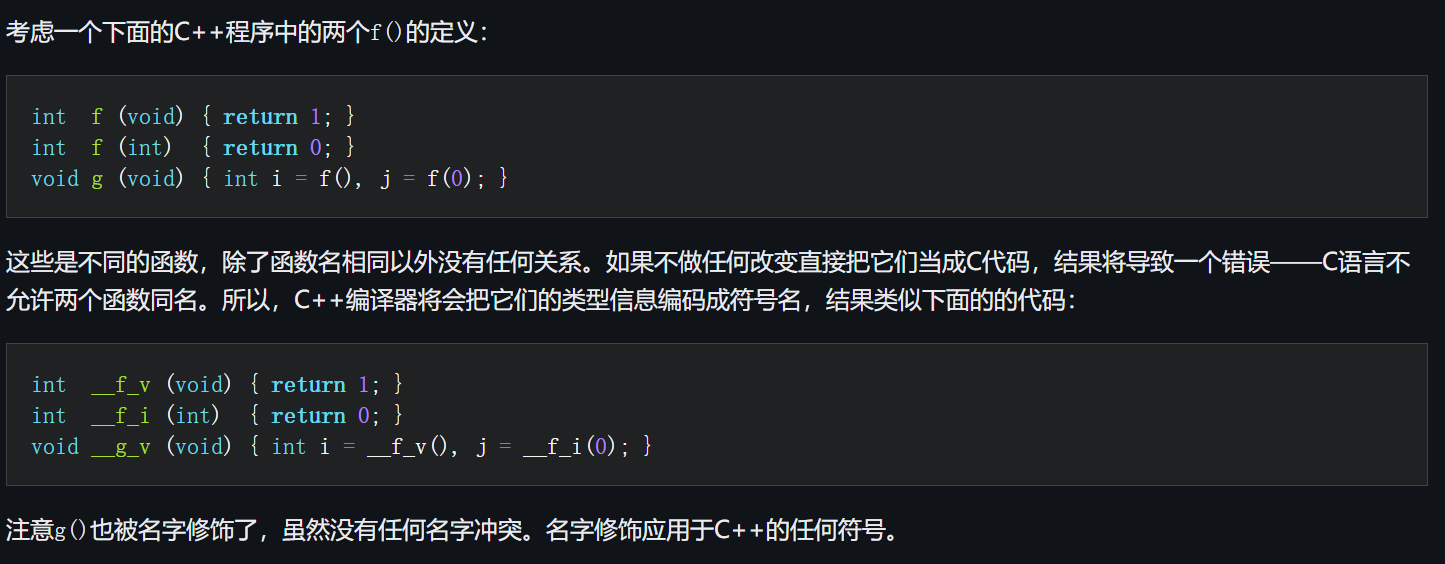

测试代码:
int f(void)
{
return 1;
}
int f(int x)
{
return 0;
}
int main(int argc, char **argv)
{
int i = f();
int j = f(1);
return 0;
}用管理员打开x64 Native Tools Command Prompt for VS 2022
Windows 下,cl 是 MSVC(Microsoft Visual C++ 编译器),dumpbin 是 用于查看二进制文件符号表 的工具。
要注意在不同平台下的结果可能不一样
cl test.cpp
#编译(Compile):将 C++ 源代码转换成目标文件(.obj)。
#汇编(Assemble):将中间代码转换成机器代码。
#链接(Link)(默认行为):将 .obj 文件与标准库链接,生成可执行文件(.exe)。
dumpbin /SYMBOLS test.obj
#这条命令的作用是 查看 test.obj 文件中的符号表,可以帮助分析 函数符号的修饰。
#/SYMBOLS 参数:列出 .obj 文件中的 符号表,包括变量、函数、调试信息等输出为:
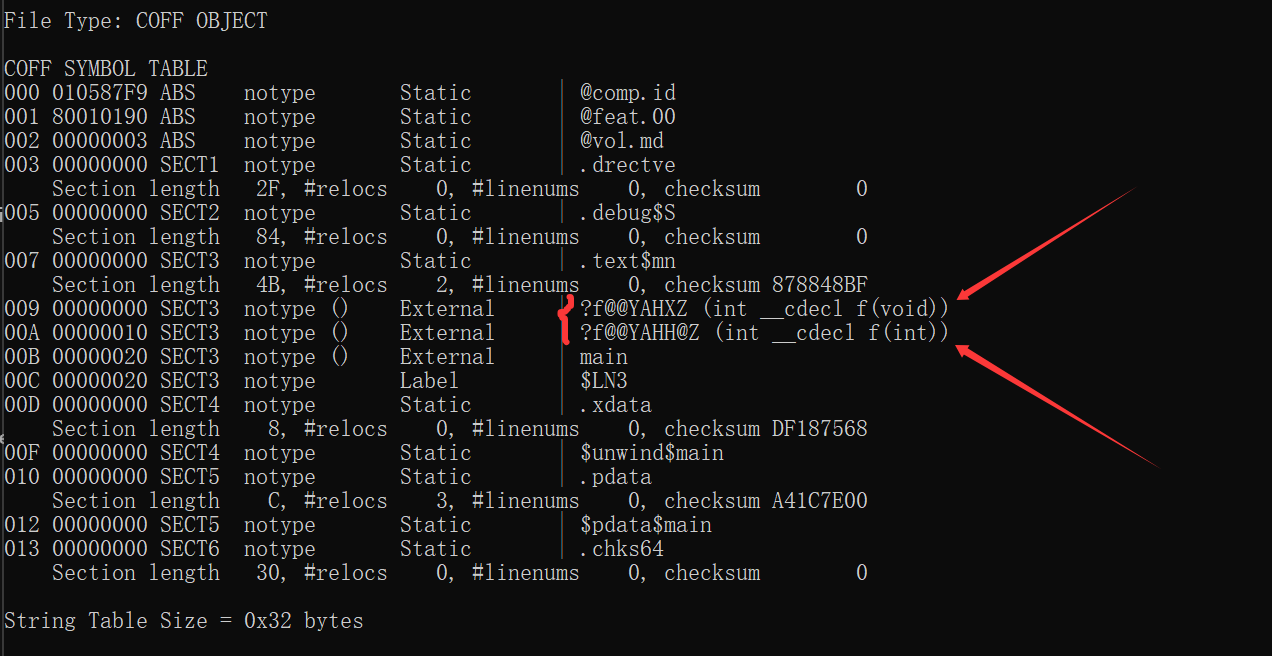
可以看到
f(void)被修饰成?f@@YAHXZ(int __cdecl f(void))
f(int)被修饰成?f@@YAHX@Z(int __cdecl f(int))
MSVC(Microsoft Visual C++) 编译器下的修饰规则:
函数的名字修饰(Decorated Name)就是编译器在编译期间创建的一个字符串。用来指明函数的定义或原型。
基本结构:
?函数名@作用域@调用约定@返回类型@参数列表@Z| 组件 | 说明 |
|---|---|
? | C++ 符号前缀(全局或类作用域的符号修饰) |
函数名 | 原始的函数名 |
@作用域@ | 若为类成员函数,则表示所属类;若为全局函数,则无此部分 |
调用约定 | 例如 YAH 代表 __cdecl |
返回类型 | 例如 YAH 中的 H 表示返回 int |
参数列表 | 依次表示参数类型 |
Z | 结束标志 |
另外
其实从做题人的角度,最好的方式是依据题目上的内容自己写一个一样的
eg:已知修饰前的内容:private: char \* __thiscall R0Pxx::My_Aut0_PWN(unsigned char \*),使用C++写出一个上面函数的例子:
#include <iostream>
class R0Pxx {
public:
R0Pxx() {
My_Aut0_PWN((unsigned char*)"hello");
}
private:
char* __thiscall My_Aut0_PWN(unsigned char*);
};
char* __thiscall R0Pxx::My_Aut0_PWN(unsigned char*) {
std::cout << __FUNCDNAME__ << std::endl;
return 0;
}
int main()
{
R0Pxx A;
system("PAUSE");
return 0;
}
//?My_Aut0_PWN@R0Pxx@@AEAAPEADPEAE@Z
__FUNCDNAME__ 是 MSVC 专属的 函数修饰名称 预定义宏,它会输出 MSVC 进行符号修饰后的函数名
UnDecorateSymbolName() 是 Windows API(来自 dbghelp.dll),用于 解析和还原 C++ 符号修饰(Name Mangling)后的名称,主要用于 MSVC 编译的二进制文件。
DWORD UnDecorateSymbolName(
PCSTR name, // 输入:被修饰的符号(Mangled Name)
PSTR outputString, // 输出:还原后的符号
DWORD maxLength, // 输出缓冲区的大小(字节)
DWORD flags // 解析选项
);参考资料:
C++ 符号修饰和函数签名 - WFApple - 博客园↗
Microsoft Visual Studio工具 - dumpbin 使用 - 知乎↗
c, c++函数名编译符号修饰符说明_c函数 前缀修饰-CSDN博客↗
20. ida操作
ida查看segment区:shift+f7
21 python一个语法
isinstance(object, classinfo)
是 Python 中的一个内置函数,用于检查一个对象是否是指定的类型或类型元组的实例。
# 检查是否是字符串类型
print(isinstance("hello", str)) # 输出: True
# 检查是否是整数类型
print(isinstance(42, int)) # 输出: True
# 检查是否是元组中的任意类型
print(isinstance(3.14, (int, float))) # 输出: True
# 检查是否是列表类型
print(isinstance([1, 2, 3], list)) # 输出: True使用:主要用于一个列表里既有int又有str型的数据
key = "happyx3"
flag = [14, '\r', 17, 23, 2, 'K', 'I', '7', ' ', 30, 20, 'I', '\n', 2, '\f', '>', '(', '@', 11, '\'', 'K', 'Y', 25, 'A', '\r']
# 将 flag 中的字符转换为 ASCII 值
flag = [ord(c) if isinstance(c, str) else c for c in flag]
for i in range(len(flag)):
flag[i] ^= ord(key[i % len(key)])
print(chr(flag[i]), end='')
#flag{3z_And0r1d_X0r_x1x1}22.android逆向的一个tip
R.layout.layout2指res/layout/ 目录下的 layout_2.xml 布局文件。
23. linux反调试(待写)
题目:[NewStarCTF 2023 公开赛道]R4ndom
24.安卓动调流程(待写)
24. xxtea
要看清楚哪里有魔改,Delta,移位都要看清楚,逐个比对
25. [NewStarCTF 2023 公开赛道]Let’s Go-
核心是识别算法,怎么看出来是AES的CBC模式加密,当然iv与调试与否有关(反调试)
26. TEA算法
ida识别TEA算法时会有一些数据类型的问题,比如__int64,QWORD,DWORD等最好转化成数组来解
27.看看算法看看语法
题目是每次进行base64加密时都会换表,这个exp使用
str.maketrans(change_table, table): 生成一个字符映射表,将change_table中的字符替换为table中的对应字符。.translate(): 对截取的子串(str1[i:i+4])应用字符替换。
因为对码表进行了替换,那么密文也相对正常的加密密文进行了替换,那么码表怎么换回来和密文怎么换回来是一样的方法
# encoding=utf-8
print("x" * 42)
# 变表base
import base64
change_table = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
table = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
str1 = 'CPaKBfUZFcNwW9qCKgyvuS2PGPQ9mttGc/wCNS0w6hDwGOSsOkOEkL5V'
key = [0x29, 0x28, 0x39, 0xa, 0x3e, 0x1e, 0x3b, 0x19, 0x0c, 0x0, 0x2e, 0x3a, 0x1, 0x18]
for i in range(0, len(str1), 4):
tmp=list(table)
new_table=[0]*64
for k in range(len(tmp)):
new_table[k]=tmp[(key[i//4]+k)%64]
change_table=''.join(new_table)
print(str(base64.b64decode(str1[i:i+4].translate(str.maketrans(change_table, table))))[2:2+3], end='')
# flag{12573882-1CF1-EB5E-C965-035B1F263C38}
28. java到jni的一个坑
java字符串传递到jni接口时,采用了GetStringUtfChars,这个函数会自动采用utf-8的解码格式。
base64解码的结果中含b”\x0c\x80”,这是因为安卓写入空字符会encode成**\xc0\x80**,python进行decode()时将报错,直接替换为**b”\x00”**即可。